
MaxCompute (ODPS) 计算中的长尾问题
数据长尾在分布式数据计算中属于很常见的问题,之前一直没有系统性的做过总结,最近在消化双十一的需求过程中,发现了不少长尾问题,所以也有机会来总结一下常见的长尾问题。
本文主要会记录在 ODPS 计算引擎侧常见的长尾现象以及优化方法。
MaxCompute(ODPS)计算本质是 MapReduce 的计算,MapReduce 通常分为三个阶段:Map 阶段、Join 阶段以及 Reduce 阶段,接下来分别针对这三个阶段,来讲讲会出现的长尾现象以及优化思路。
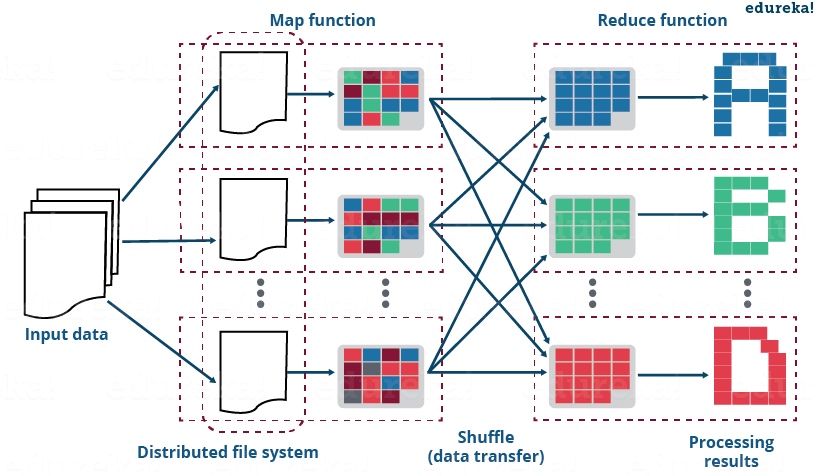
Map 阶段长尾
Map 阶段一般是 MapReduce 在 Input 之后的第一阶段,该阶段数据从文件系统读入到 Map 端。数据在 Map 阶段主要会经过两类计算:
- 每输入一个文件分片,都会被分配到一个 map instance 进行计算。
- 在 Map 阶段也会进行一次预聚合,数据通过 key 的 hash 分配到不同的 instance 上,目的是为了减少数据在网络传输中的负责,最终减少 reduce 端的数据量。
上面两个阶段,都会出现长尾现象
- 如果文件分片大小分布不均,在 input data 阶段,会导致有些 map 准备数据比较快,有些 map 准备数据比较慢
- 如果是在 map 预聚合阶段,有些热点的 key 对应的数据量特别多,会导致长尾,主要是 count distinct 操作
针对上面两种典型的情况,有如下优化思路:
- 如果是文件分片大小不均,一般我们就想办法把小文件进行合并,保证各个文件分片的数据量级保持在同一个数量级上,这个操作可以手动操作,也可以通过 map 阶段的参数进行设置。
1 | # odps 设定控制文件被合并的最大阈值,单位M,默认64M |
- 如果在 map 域聚合阶段发生长尾,则一般可通过
distribute by rand(),通过随机数分布的方式来打乱数据,从而平衡 map 端的并发数据量。下面分享一个案例
1 | SELECT COUNT(DISTINCT buyer_id) |
Join 阶段长尾
Join 阶段的时候,一般都会把相同的 Join key 分发到同一个 instance 里,那么一样的道理,如果某个 Key 上的数据量特别大,就会产生该 Key 对应的 instance 处理数据的时间要比其他 instance 要长很多。
针对 Join 阶段的长尾,一般也有两个现象:
- Join 的某张表比较小,另外的表很大,这种情况可以使用 MapJoin,将 Join 的长尾问题过度到 Map 阶段的长尾问题。
1 | SELECT /*+ MAPJOIN(m2) */ |
- Join 的两张表都比较大,这时候就要 By case 的分析,把一些特别大的热门 key 剥离出来,落到临时表。相当于把数据分为大 Key 的数据集和非大 Key 的数据集,最后把两类的数据再 Union All 到一起。
Reduce 阶段长尾
Reduce 负责 Map 阶段处理后 KV 对数据,一般会进行 Count、AVG、MIN、MAX 等聚合类的操作。
在 Reduce 阶段,造成长尾的原因一般都是 KV 中的 Key 分发的不均匀导致,不同的 reduce instance 处理的数据量不一致,就会出现 reduce 长尾。常见的现象有:
- Count Distinct 造成的长尾,Distinct 执行的原理是根据 Distinct 的字段和 Group By 的字段共同组成 Key 之后将数据分发到 reduce 端,这就会导致数据无法在 Map Shuffle 阶段先做一次 Group By 操作,而是将所有的数据都传到 reduce 端,当 Key 的数据没有很均匀的分布时,这时候就会造成 reduce 长尾。
- Join 阶段会存在热点 Key(比如是 Null 值),会导致热点 Key 被分发到同一个 reduce 的 instance 上,造成 reduce 长尾。
- 动态分区过多导致的 reduce 长尾。
- Map 端的随机化导致的 reduce 长尾。
针对上面的几种情况,有如下的优化思路:
- Count Distinct 的任务优化,目前有两个思路
- 比如我们需要计算原表维度的支付买家数、新人买家数等去重指标,可以先发起子查询,先做一次原表维度+user_id 的 group by,分别 count 出 地区,设备等统计口径的 user_id,然后在子查询外 group by 原表粒度,当 count 的值 >= 0 时,则计入统计,否则就不计入,对应伪码如下:
1 | SELECT m.country |
- 另一种思路是参考 redis 中的两个 set 合并的方案,ODPS 提供了 bitset(bitmap) 方案,具体可以参考:RoaringBitmap,后面单独写一篇博客讨论。
- Join 存在热点 Key(Null 值)
跟 Map 阶段的优化一样,可以将一些热点的 key 做一下随机处理,来分发数据到不同的 reduce instance
1 | LEFT OUTER JOIN ( |
- 动态分区过多
这个情况主要配置一个参数,关闭 reduce task
1 | set odps.sql.reshuffle.dynamicpt=false; |
- Map 端随机化导致的 reduce 长尾
Map 端长尾时,我们使用过 distribute by rand() 函数来打乱 Map 端 Key 分布,但是这样造成 reduce 端长尾。这种情况我们也可以通过提高 reduce 并发
1 | set odps.sql.reducer.instances=1000; |
总结
举了这么多例子,大家应该也能感受到,如果把治理长尾任务分分类,可以分成以下几种情况:
- 用并发换计算,适当提高并发度;
- 用存储换计算,将一些可复用的中间结果,物化下来,避免重复计算,而且存储的成本一般都要比计算的成本低很多;
- 减少 shuffle 的数据量,能在 Map 阶段完成的就在 Map 阶段完成,分布式计算的瓶颈永远都是在网络 IO,在敲代码阶段就要考虑到这一点;
- 减少 reduce 的 KV 对,尽量保证分发到不同 instance 的 KV 对在一个数量级。
互联网已经过了野蛮生长的阶段,在各个业务都在精细化管理的今天,未来几年对代码性能的优化也会越来越受到关注。有些历史任务之前根本就没有考虑过性能问题,比如我就看到我们部门某些任务,光计算费用,每年都要花大几十万,稍微优化一下,就能省下80-90%的计算费用,而在业务增长停滞的今天,能省下多少钱,反而更能体现你的价值。