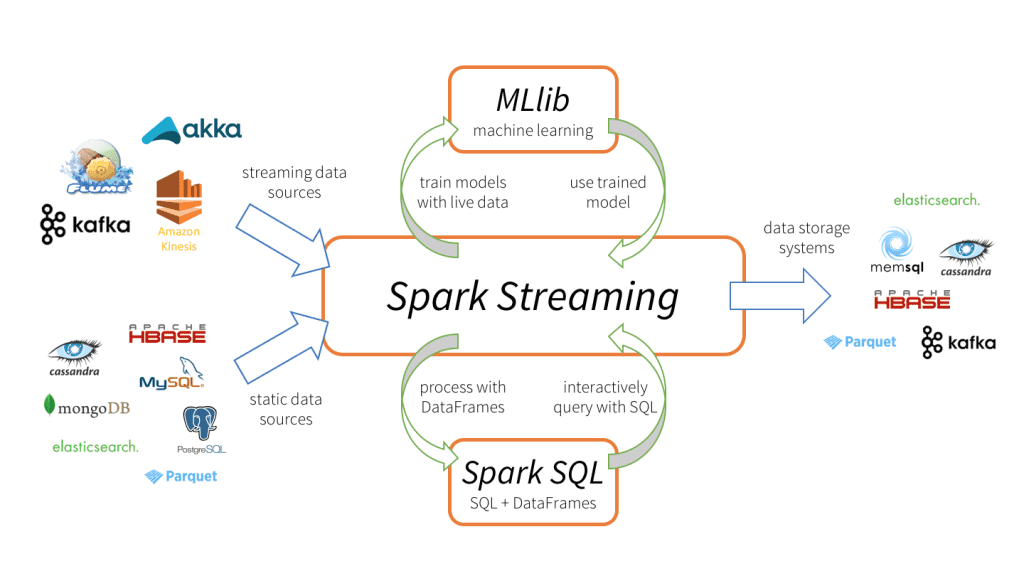
由于数据时效性的原因,实时预测在生产上越来越重要,Spark ML 模型中,常见的实时预测方案有两种:
将训练后的模型转化为通过 PMML 模型类型,实现跨平台同步预测。
利用 Spark Streaming 加载 Spark ML 模型,订阅消息后,实现实时异步预测。
本文介绍第二种方法,通过 spark streaming 订阅 kakfa 消息,加载 spark ml 模型,实时进行特征转换及预测。
Spark Streaming 作为 Spark 组建之一,可以无缝集成 Spark ML 和 Spark SQL。
运行环境 pom.xml 依赖如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 <properties> <spark.version>2.3.1</spark.version> <scala.version>2.11.11</scala.version> <mysql.version>5.1.49</mysql.version> <fastjson.version>1.2.70</fastjson.version> </properties> <dependencies> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>${fastjson.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-reflect</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-compiler</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql-kafka-0-10_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql-kafka-0-10_2.11</artifactId> <version>${spark.version}</version> </dependency> </dependencies>
训练模型及持久化 为了操作简单,我们先用 Spark ML 内的 Feature + LR 包简单建立一个模型,并持久化到本地。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import org.apache.spark.SparkConf import org.apache.spark.ml.Pipeline import org.apache.spark.ml.classification.LogisticRegression import org.apache.spark.ml.feature.{HashingTF, Tokenizer} import org.apache.spark.sql.SparkSession /** * FileName: PipelineModelDemo * Author: zhangzhanqi * Date: 9/10/20 2:36 PM * Description: */ object PipelineModelDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(getClass.getSimpleName).setMaster("local[*]") val sparkSession = SparkSession.builder().config(conf).getOrCreate() val training = sparkSession.createDataFrame(Seq( (0L, "training test A", 1.0), (1L, "dsa fdse r B", 0.0), (2L, "spark streaming test C", 1.0), (3L, "dasg bb cfo zxy", 0.0) )).toDF("id", "text", "label") // 分词 val tokenizer = new Tokenizer() .setInputCol("text") .setOutputCol("words") // 词频 Term Frequency val hashingTF = new HashingTF() .setNumFeatures(1000) .setInputCol(tokenizer.getOutputCol) .setOutputCol("features") // 拟合模型 val lr = new LogisticRegression() .setMaxIter(10) .setRegParam(0.001) val pipeline = new Pipeline().setStages(Array(tokenizer, hashingTF, lr)) val model = pipeline.fit(training) model.write.overwrite().save("file:///Users/zhangzhanqi/Downloads/spark-lr-model") } }
实时流加载模型及预测 训练完模型后,我们就可以通过 Spark Streaming 加载模型,订阅 Kafka 消息,来实时预测数据,这里的逻辑大致是:订阅 Kafka 消息 => 消费消息 => 消息有效性验证 => 消息转 Dataframe => 预测结果。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 import com.alibaba.fastjson.JSON import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.SparkConf import org.apache.spark.ml.PipelineModel import org.apache.spark.sql.SparkSession import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe import org.apache.spark.streaming.kafka010.KafkaUtils import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent /** * FileName: StreamingMachineLearningDemo * Author: zhangzhanqi * Date: 9/9/20 11:24 AM * Description: */ object StreamingMachineLearningDemo { def isJsonValid(jsonString: String): Boolean = { try { JSON.parseObject(jsonString) true } catch { case ex: Exception => { println(ex.getMessage) false } } } def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(getClass.getSimpleName).setMaster("local[2]") val spark = SparkSession.builder().config(conf).getOrCreate() import spark.implicits._ // 一秒 1 个 batch 的消费 val ssc = new StreamingContext(spark.sparkContext, Seconds(1)) // local kafka consumer val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "localhost:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "1", "auto.offset.reset" -> "latest", "enable.auto.commit" -> (false: java.lang.Boolean) ) val topics = Array("lr_model_topic") val stream = KafkaUtils.createDirectStream[String, String]( ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParams) ) val lrModel = PipelineModel.load("file:///Users/zhangzhanqi/Downloads/spark-lr-model") // 过滤无效 json 流 val source = stream.map(_.value()).filter(isJsonValid).map(JSON.parseObject) source.foreachRDD(rdd => { if (rdd.count() > 0) { val data = rdd.map(jsonObj => (jsonObj.getLong("id"), jsonObj.getString("text"))).toDF("id", "text") val prediction = lrModel.transform(data).select("id", "text", "probability", "prediction") prediction.show(false) } }) ssc.start() ssc.awaitTermination() } }
测试数据 现在我们在 kafka producer 端发送一条消息,看是否在 spark streaming 有消费
控制台启动 kafka producer 并指定 topic,发送一条测试数据
1 2 ➜ ~ kafka-console-producer --broker-list localhost:9092 --topic lr_model_topic >{"id":1,"text":"spark model test"}
一秒后 SparkStreaming 端收到消息并且得出模型预测结果,即表示成功:
1 2 3 4 5 +---+----------------+-----------------------------------------+----------+ |id |text |probability |prediction| +---+----------------+-----------------------------------------+----------+ |1 |spark model test|[0.020994583288024206,0.9790054167119758]|1.0 | +---+----------------+-----------------------------------------+----------+