
基于 Spark ML + Jieba + Jaccard 计算文本相似度
背景需求
最近在做短视频的相似视频推荐,初期不涉及语义分析及图像检测,所有单纯使用视频标题作为文本,来度量视频库中的相似视频,baseline 选择了使用 Jarccard 相似系数,简单而且效果明显。
整体步骤可以参考下图:
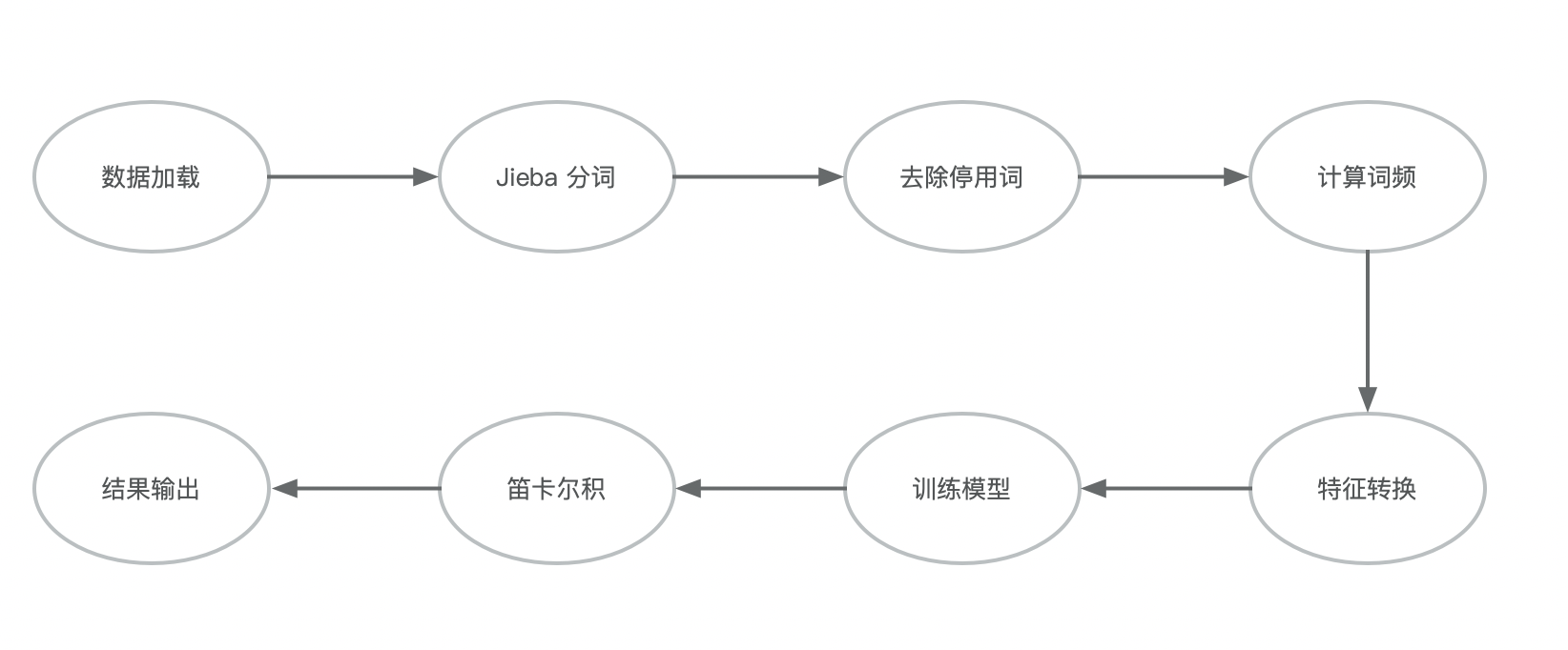
用 Spark 做特征工程时,推荐可以先看下下面的文档
Extracting, transforming and selecting features - Spark 2.3.1 Documentation
Jaccard 系数
先介绍下 Jarccard 系数,Jarccard 相似系数(Jaccard similarity coefficient )表示两个集合 A 和 B 的交集元素在 A 和 B 的并集中所占的比例,用符号 J(A, B) 表示:
$$J(A, B) = \frac{ \mid A \bigcap B \mid} {\mid A \bigcup B \mid} $$
Jarccard 相似系数是衡量两个集合的相似度的一种指标
Jieba 分词
Spark 中可以使用 Tokenizer 或 RegexTokenizer 来进行分词,两者的区别在于 Tokenizer 默认通过 空格 进行分词;而 RegexTokenizer 则可以通过正则表达式进行自定义匹配。
英文分词相对简单,默认词与词之间就有空格。中文的话,我们可以用 jieba 或相关的开源库进行分词。
1 | <dependency> |
1 | import com.huaban.analysis.jieba.{JiebaSegmenter, SegToken} |
1 | +---+--------------------------+-------------------------------------+--------------------------------------------------+ |
停用词维护
Spark 中自带停用词的词袋 StopWordsRemover,但是该模块仅支持英语,发育,德语,意大利语等西方语言,并没有对中文进行维护。所以我们需要自己维护一系列的停用词,用来去除 “的”,“哦”,“好” 等相关常用词,以及去除“!”,“#”等标点符号,减少这些词对最终结果的影响。比如上面的例子,可以维护一个 cn_stoplist,来把一些常用词给过滤掉,那么我们可以改造下上面 segment 这个 UDF。
1 | // 去除下面三个词 |
那么分词结果就会变成:
1 | +---+--------------------------+----------------------------------+----------------------------------------------+ |
词频与特征转换
去掉了停用词以及分词之后,我们就可以对这些词进行向量化的操作,Spark 中我们选择 CountVectorizer,来对分词后的数据进行向量化并做词频的统计。
1 | val cvModel = new CountVectorizer() |
拟合后,我们就可以得到如下的结果:
1 | +---+--------------------------+----------------------------------+----------------------------------------------+--------------------------------------------------------------------------------+ |
计算 Jaccard 系数
Spark 中没有直接计算 Jaccard 的模块,但是别急,我们可以用 MinHashLSH 来近似 Jaccard 系数,查了官方文档,MinHashLSH 是 Jaccard 距离的 LSH 系列,基本思想是:如果两个文本在原有的数据空间是相似的,那么分别经过哈希函数转换以后的它们也具有很高的相似度;相反,如果它们本身是不相似的,那么经过转换后它们应仍不具有相似性。
LSH 算法详情可以参照:LSH算法 - 知乎 这篇文章的解释。
1 | val mhModel = new MinHashLSH().setNumHashTables(100).setInputCol("features").setOutputCol("hashValues").fit(vectorizedDF) |
approxSimilarityJoin 方法让两个数据集进行笛卡尔积,使之进行两两比较,后面的 0.8 这个数表示对计算结果的阈值设定,数值越小,过滤出来的数据越“相似”,相对的数量也越少。
1 | +-----+--------------------------+-----+--------------------------+-------+ |
至此我们在 Spark ML 包中,利用 Jieba + Jarrcard 系数计算得出了一组文本集中的相似度。
Reference
在Spark上基于Minhash计算jaccard相似度
Extracting, transforming and selecting features
Locality-Sensitive Hashing, LSH