
Spark Machine Learning 之集成 TensorFlow 模型并实现离线预测
结合 TensorFlow 在深度学习及传统机器学习上的优势,加上 Spark 在分布式及计算上的优势,实现 Spark 预测 TensorFlow 模型的方案
TensorFlow 本身是 Python 下的框架,但官方也提供了 Java API,支持 Java 应用调用 TensorFlow 各个接口,只是没有 Python API 那么全面。
那么作为 Java 的亲儿子 Scala,两者最终都是编译成 Class 在 JVM 上运行,用其开发的 Spark 应用也自然支持所有 Java 自带的 API 及第三方 API,我们只需要把 TensorFlow Java API 引入 Scala 项目中,就可以调用到了。
贴上 TensorFlow Java 的官方连接
安装 Java 版 TensorFlow
整个模型流转的流程图如下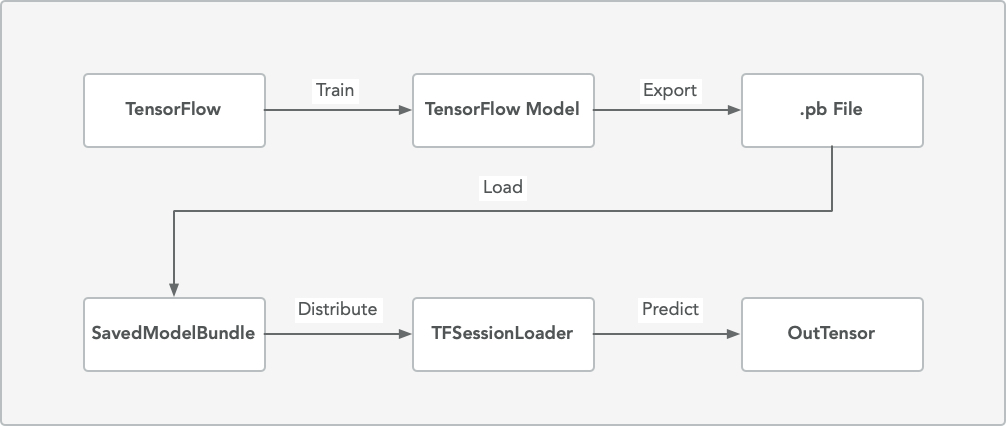
集群 Version
我的 Scala、Spark 等相关环境的版本信息如下
1 | <properties> |
TensorFlow Saved Model
本文不介绍 TensorFlow 模型如何训练,只关注最终输出的模型文件是否是 TensorFlow 通用的 PB 模型,它的文件结构如下
1 | saved_model |
在 Spark 应用中导入模型文件
拿到模型后,下一步我们把模型/模型文件夹导入到 Spark 集群中,由于我们是要多 Worker 的分布式预测,也必须把模型相关内容放到分布式存储系统中,通常的做法是上传到 HDFS,也可以放到阿里云 OSS 等对象存储的地方
在 Spark 中 import 相关类
1
import org.tensorflow.{SavedModelBundle, Tensor}
初始化 SavedModelBundle
由于 SavedModelBundle 默认是不可序列化的类,所以在 SparkConf 中通过 KryoSerializer 将该类配置序列化1
2
3
4val sparkConf = new SparkConf()
.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array(classOf[SavedModelBundle]))
...分发模型文件
接下来将模型分发到 Spark 的计算节点 Executor,使得各节点可以在“本地”访问到模型文件1
2
3
4# addFile(path: String, recursive: Boolean)
# path: 模型路径
# recursive: 是否递归,如果模型是个文件夹,则设置会 true,spark 会递归的载入该路径下的所有文件
spark.sparkContext.addFile('模型地址', true)
在 Spark 计算节点载入模型预测
- 载入模型
各 Executor 本地拿到模型后,我们就可以在每个 Executor 中载入模型,并实例化 TensorFlow Session,因为 TFSessionLoader 这个实例可以复用,所以我们可以简单通过单例模式来载入 TensorFlow Session,避免重复实例化
1 | import org.apache.spark.SparkFiles; |
- 预测模型
拿到 TFSession 之后,我们就可以在 UDF 内批量预测了,下面是伪码
1 | val getPredictScore = udf { userVector: MLSparseVector => |
其中的 scores 就是模型预测出来的分数
优化建议
- 一定要关掉相关 Tensor 资源,否则会 OOM
- 建议批量处理预测,比如针对 user 和 item 的预测,如果 item 和 user 不在一个量级(比如 user 是千万级,item 是几千几百),可以一个 user 批量预测所有的 item,保证效率