val bucketColumn = FeatureColumn.userBucketColumn val bucketColumnName: ArrayBuffer[String] = new ArrayBuffer[String]()
for (item <- bucketColumn) { bucketColumnName.append(item._1) }
val assemblerBucket = new VectorAssembler() .setInputCols(dataset.columns.filter(columnName => bucketColumnName.contains(columnName))) .setOutputCol("assemblerBucketUser") val minMaxScaler = new MinMaxScaler() .setInputCol("assemblerBucketUser") .setOutputCol("scalerVectorUser")
val indexers = FeatureColumn.userIndexerColumn.toArray.map { inColumn => new StringIndexer() .setInputCol(inColumn) .setOutputCol(s"${inColumn}_idx") .setHandleInvalid("keep") }
val oneHotColumn = FeatureColumn.userOneHotColumn
val oneHotEncoderEstimator = new OneHotEncoderEstimator() .setInputCols(oneHotColumn.toArray ++ FeatureColumn.userIndexerColumn.map(x => x + "_idx") ) .setOutputCols(oneHotColumn.toArray.map(x => x + "_oneHotVec") ++ FeatureColumn.userIndexerColumn.map(x => x + "_oneHotVec")) .setHandleInvalid("keep") .setDropLast(false)
val assemblerVector = new VectorAssembler() .setInputCols(oneHotEncoderEstimator.getOutputCols.filter(x => x.endsWith("_oneHotVec")) ++ Array("scalerVectorUser")) .setOutputCol("ufeatures")
val pipeline = new Pipeline().setStages(Array(assemblerBucket, minMaxScaler) ++ indexers ++ Array(oneHotEncoderEstimator, assemblerVector)) pipeline.fit(dataset)
val categoricalFeatures: Map[Int, Int] = getCategoricalFeatures(dataset.schema($(featuresCol)))
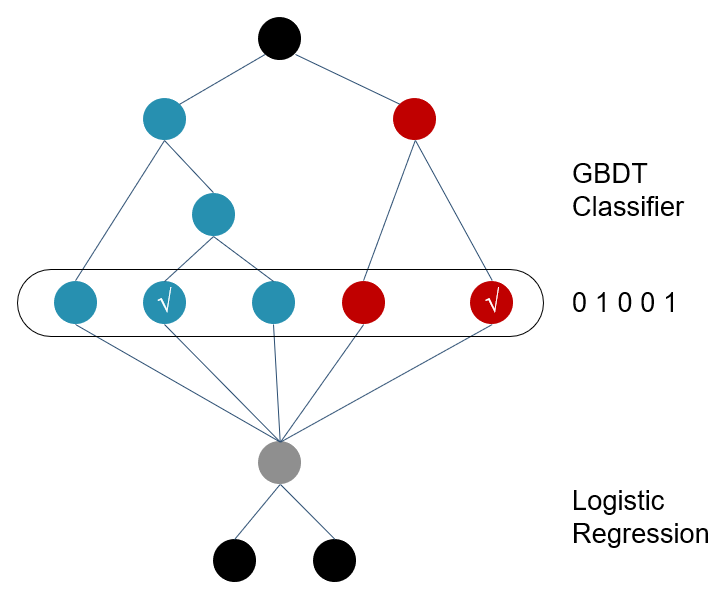
// GBT only supports 2 classes now. val oldDataset: RDD[OldLabeledPoint] = dataset.select(col($(labelCol)), col($(featuresCol))).rdd.map { case Row(label: Long, features: Vector) => require(label == 0 || label == 1, s"GBTClassifier was given" + s" dataset with invalid label $label. Labels must be in {0,1}; note that" + s" GBTClassifier currently only supports binary classification.") OldLabeledPoint(label, new OldDenseVector(features.toArray)) }
val strategy = getOldStrategy(categoricalFeatures) val boostingStrategy = new OldBoostingStrategy(strategy, getOldLossType, getGBTMaxIter, getStepSize)
// train a gradient boosted tree model using boostingStrategy. val gbtModel = GradientBoostedTrees.train(oldDataset, boostingStrategy) gbtModel