背景介绍
pyspider 架构,大概的流程如下图所示:
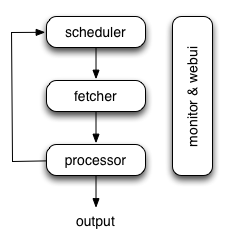
整个 pyspider 的各个模块间的任务传递是由**消息队列**传输的,其中任务的调度则是由「scheduler」模块控制,所以按作者的意思,除了「scheduler」调度模块只能单点,其他的「fetcher」,「processor」,甚至是「monitor & webui」,都可以实现多实例分布式部署。
这样一来分布式 pyspider 的瓶颈就在单点的 「scheduler」 节点的消费能力了,实际跑起来观察后发现确实「processor」到「scheduler」发送任务的队列经常消费不过来。
言归正传
之前将单机的 pyspider 部署在一台机子上,这一台负责「数据存储」,「消息队列」,「任务调度」,「URL请求」,「页面处理」全部的爬虫相关任务,导致 CPU 利用率一直很高。
所以现在单独开了一台机子,专门负责「URL请求」和「页面处理」,即上述的「fetcher」和「processor」模块。
主机地址、数据库、消息队列
- 爬虫机器1: 192.168.1.33
- 爬虫机器2: 192.168.1.71
- 数据库: mongodb://192.168.1.33:27017
- 消息队列: redis://192.168.1.33:6379
依赖安装
- docker & docker-compose
- docker pull pyspider
- docker pull redis
- docker pull mongodb
非爬虫部分配置
docker 配置网络接口:docker network create --driver bridge pyspider
数据库服务:我使用 mongoDB,由于之前就把服务起起来了,所以我没有进行 docker 封装,如果你是新起一个分布式爬虫,建议数据库服务也使用Docker。
消息队列服务:redis。命令:docker run --network=pyspider --name redis -d -p 6379:6379 redis
- 注意: 我下面用的非原生 pyspider,因为我需要依赖一些 pyspider 没有的库,请注意替换 (
my/pyspider -> binux/pyspider)
爬虫机器 1 配置
1
2
3
4
5
6
| docker run --network=pyspider --name scheduler -d -p 23333:23333 --restart=always my/pyspider\
--taskdb "mongodb+taskdb://192.168.1.33:27017/taskdb" \
--resultdb "mongodb+resultdb://192.168.1.33:27017/resultdb" \
--projectdb "mongodb+projectdb://192.168.1.33:27017/projectdb" \
--message-queue "redis://192.168.1.33:6379/0" \
scheduler --inqueue-limit 10000 --delete-time 3600
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| version: '2'
services:
phantomjs:
image: 'my/pyspider:latest'
command: phantomjs
cpu_shares: 256
environment:
- 'EXCLUDE_PORTS=5000,23333,24444'
expose:
- '25555'
mem_limit: 256m
restart: always
phantomjs-lb:
image: 'dockercloud/haproxy:latest'
links:
- phantomjs
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- restart: always
fetcher:
image: 'my/pyspider:latest'
command: '--message-queue "redis://192.168.1.33:6379/0" --phantomjs-proxy "phantomjs:80" fetcher --xmlrpc'
cpu_shares: 256
environment:
- 'EXCLUDE_PORTS=5000,25555,23333'
links:
- 'phantomjs-lb:phantomjs'
mem_limit: 256m
restart: always
fetcher-lb:
image: 'dockercloud/haproxy:latest'
links:
- fetcher
volumes:
- /var/run/docker.sock:/var/run/docker.sock
restart: always
processor:
image: 'my/pyspider:latest'
command: '--projectdb "mongodb+projectdb://192.168.1.33:27017/projectdb" --message-queue "redis://192.168.1.33:6379/0" processor'
cpu_shares: 256
mem_limit: 256m
restart: always
result-worker:
image: 'my/pyspider:latest'
command: '--taskdb "mongodb+taskdb://192.168.1.33:27017/taskdb" --projectdb "mongodb+projectdb://192.168.1.33:27017/projectdb" --resultdb "mongodb+resultdb://192.168.1.33:27017/resultdb" --message-queue "redis://192.168.1.33:6379/0" result_worker'
cpu_shares: 256
mem_limit: 256m
restart: always
webui:
image: 'my/pyspider:latest'
command: '--taskdb "mongodb+taskdb://192.168.1.33:27017/taskdb" --projectdb "mongodb+projectdb://192.168.1.33:27017/projectdb" --resultdb "mongodb+resultdb://192.168.1.33:27017/resultdb" --message-queue "redis://192.168.1.33:6379/0" webui --scheduler-rpc "http://192.168.1.33:23333/" --fetcher-rpc "http://fetcher/"'
cpu_shares: 256
environment:
- 'EXCLUDE_PORTS=24444,25555,23333'
ports:
- '5001:5000'
links:
- 'fetcher-lb:fetcher'
mem_limit: 256m
restart: always
networks:
default:
external:
name: pyspider
|
将上面写到的 db 和 queue 连接改为你自己的对应地址:
taskdb: mongodb+taskdb://192.168.1.33:27017/taskdb
projectdb: mongodb+projectdb://192.168.1.33:27017/projectdb
resultdb: mongodb+resultdb://192.168.1.33:27017/resultdb
message-queue: redis://192.168.1.33:6379/0
构建镜像,创建、启动服务
- 前台启动:
docker-compose up
- 后台启动:
docker-compose up -d
配置 processor,fetcher,result-worker 模块的进程数量
docker-compose scale phantomjs=2 processor=4 result-worker=2
pyspider 的网络请求基于 tornado, 而 tornado 使用了一种单线程事件循环的方式,使用异步非阻塞的方式去做网络请求,所以多个节点对 fetcher 效率的影响并不会很大。
至此我们就在「爬虫机器1」上就启动了 2 个「phantomjs」,1 个「fetcher」, 4 个「processor」, 2 个 「result-worker」 组成的多模块 pyspider,接下来在「爬虫机器2」上完成类似配置。
爬虫机器 2 配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| version: '2'
services:
phantomjs:
image: 'my/pyspider:latest'
command: phantomjs
cpu_shares: 256
environment:
- 'EXCLUDE_PORTS=5000,23333,24444'
expose:
- '25555'
mem_limit: 256m
restart: always
phantomjs-lb:
image: 'dockercloud/haproxy:latest'
links:
- phantomjs
volumes:
- /var/run/docker.sock:/var/run/docker.sock
restart: always
fetcher:
image: 'my/pyspider:latest'
command: '--message-queue "redis://192.168.1.33:6379/0" --phantomjs-proxy "phantomjs:80" fetcher --xmlrpc'
cpu_shares: 256
environment:
- 'EXCLUDE_PORTS=5000,25555,23333'
links:
- 'phantomjs-lb:phantomjs'
mem_limit: 256m
restart: always
fetcher-lb:
image: 'dockercloud/haproxy:latest'
links:
- fetcher
volumes:
- /var/run/docker.sock:/var/run/docker.sock
restart: always
processor:
image: 'my/pyspider:latest'
command: '--projectdb "mongodb+projectdb://192.168.1.33:27017/projectdb" --message-queue "redis://192.168.1.33:6379/0" processor'
cpu_shares: 256
mem_limit: 256m
restart: always
result-worker:
image: 'my/pyspider:latest'
command: '--taskdb "mongodb+taskdb://192.168.1.33:27017/taskdb" --projectdb "mongodb+projectdb://192.168.1.33:27017/projectdb" --resultdb "mongodb+resultdb://192.168.1.33:27017/resultdb" --message-queue "redis://192.168.1.33:6379/0" result_worker'
cpu_shares: 256
mem_limit: 256m
restart: always
networks:
default:
external:
name: pyspider
|
构建镜像,创建、启动服务
- 后台启动:
docker-compose up -d
- 前台启动:
docker-compose up
配置 processor,fetcher,result-worker 模块的进程数量
docker-compose scale phantomjs=2 processor=4 result-worker=2
参考
