
Hadoop2.6 与 Spark1.5 的分布式集群部署流程
机子是两台阿里云 ECS 上的实例,系统都是 CentOS 7.2,未预装任何东西,所以本教程可以帮助你从 0 开始搭建 Spark 分布式集群。下面是集群介绍
| Hosts | IP Address | Configuration | Environment |
|---|---|---|---|
| Master | 192.168.1.77 | CPU: 2 cores RAM: 8G | JDK: 1.8.0_181 Scala: 2.10.6 Hadoop: 2.7.6 Spark: 1.5.2 Python: 2.7.5 |
| Slave | 192.168.1.78 | CPU: 2 cores RAM: 8G | JDK: 1.8.0_181 Scala: 2.10.6 Hadoop: 2.7.6 Spark: 1.5.2 Python: 2.7.5 |
Environment 会在下面依次安装。
文章分为三步:准备阶段,Hadoop 安装配置阶段,Spark 安装配置阶段。
准备:设置 Hosts
Master
追加 Hosts 文件内容:
1
vim /etc/hosts
1
2192.168.1.77 master
192.168.1.78 slave追加 network 内容:
1
vim /etc/sysconfig/network
1
2NETWORKING=yes
HOSTNAME=master
Slave
打开 Hosts 文件:
1
vim /etc/hosts
1
2192.168.1.77 master
192.168.1.78 slave追加 network 内容:
1
vim /etc/sysconfig/network
1
2NETWORKING=yes
HOSTNAME=master
准备:关闭 Selinux 和防火墙 Firewall
Master
修改 Selinux 配置文件:
1
vim /etc/selinux/config
1
SELINUX=disabled
1
2
3
4
5
6
7
8
9
10
11# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted关闭防火墙 Firewall:
1
ipdatable -F;
查看防火墙是否关闭:
1
iptabls -nvL
1
2
3
4
5
6
7
8
9[root@izbp11ddoyj3i3tqpvtim9z conf]# iptables -nvL
Chain INPUT (policy ACCEPT 1421K packets, 606M bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 851K packets, 1534M bytes)
pkts bytes target prot opt in out source destination重新启动实例
Slave
修改 Selinux 配置文件:
1
vim /etc/selinux/config
1
SELINUX=disabled
1
2
3
4
5
6
7
8
9
10
11# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted关闭防火墙 Firewall:
1
ipdatable -F;
查看防火墙是否关闭:
1
iptabls -nvL
1
2
3
4
5
6
7
8
9[root@izbp11ddoyj3i3tqpvtimaz conf]# iptables -nvL
Chain INPUT (policy ACCEPT 1421K packets, 606M bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 851K packets, 1534M bytes)
pkts bytes target prot opt in out source destination重新启动实例
准备:配置免密钥登录
Master
ssh-keygen 命令
1
2
3[root@izbp11ddoyj3i3tqpvtim9z ~]# ssh-keygen
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys slave:~/.ssh/注:第一次连接时,输入 yes 继续连接。
ssh-keygen之后,一路回车。运行结束后,在~/.ssh/目录下,会生成两个新文件id_rsa和id_rsa.pub, 即私钥和公钥。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys将公钥输出到authorized_keys
scp ~/.ssh/authorized_keys slave:~/.ssh/传到 Slave 节点(已配置域名映射)测试是否可免密钥登录 Slave
1
2
3
4
5
6
7
8
9[root@izbp11ddoyj3i3tqpvtim9z ~]# ssh slave
Last login: Tue Aug 21 17:58:08 2018 from 192.168.1.77
Welcome to Alibaba Cloud Elastic Compute Service !
[root@izbp11ddoyj3i3tqpvtimaz ~]# exit
logout
Connection to slave closed.
[root@izbp11ddoyj3i3tqpvtim9z ~]#
准备:安装 Java
Master
下载 JDK ,我使用
jdk-8u181-linux-x64.tar.gz,点击这里下载解压 JDK
1
2tar zxvf jdk-8u181-linux-x64.tar.gz
mv jdk1.8.0_181 /usr/localJDK 环境变量
1
vim /etc/profile.d/java.sh
1
2
3export JAVA_HOME=/usr/local/jdk1.8.0_181
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar使环境变量生效
1
2source /etc/profile.d/java.sh
java -version1
2
3
4[root@izbp11ddoyj3i3tqpvtim9z local]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)将 JDK 压缩包和 JDK 配置文件传给 Slave
1
2scp jdk-8u181-linux-x64.tar.gz slave:/usr/local
scp /etc/profile.d/java.sh slave:/etc/profile.d
Slave
解压 JDK
1
2cd /usr/local
tar zxvf jdk-8u181-linux-x64.tar.gz使环境变量生效
1
2source /etc/profile.d/java.sh
java -version1
2
3
4
5[root@izbp11ddoyj3i3tqpvtimaz ~]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
[root@izbp11ddoyj3i3tqpvtimaz ~]#
Hadoop:安装
Master
下载 Hadoop2.7.6 安装包,可点击这里下载
解压 及 新建文件夹
1
2
3
4tar zxvf hadoop-2.7.6.tar.gz
mv hadoop-2.7.6 /usr/local
cd /usr/local/hadoop-2.7.6
mkdir tmp dfs dfs/data dfs/name目录 ` /tmp ` ,用来存储临时生成的文件 目录 ` /dfs ` ,用来存储集群数据 目录 ` /dfs/data` ,用来存储真正的数据 目录 ` /dfs/name` ,用来存储文件系统元数据安装 rsync
1
yum install -y rsync
将 Master 配置迁移到 Slave
1
rsync -av /usr/local/hadoop-2.7.6 slave:/usr/local
Slave
无需其他变动
Hadoop:配置
Master
core-site.xml
1
vim /usr/local/hadoop-2.7.6/etc/hadoop/core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.7.6/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>上述
hadoop.tmp.dir变量的路径需要改成你自己的路径。
变量fs.defaultFS保存了 NameNode 的位置,HDFS 和 MapReduce 组件都需要它,这也是它出现在core-site.xml文件中而不是hdfs-site.xml文件中的原因。hdfs-site.xml
1
vim /usr/local/hadoop-2.7.6/etc/hadoop/hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.7.6/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.7.6/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>变量
dfs.replication指定了每个 HDFS 数据块的复制次数,即 HDFS 存储文件的副本个数,默认为 3,如果不修改,DataNode 少于 3 台就会报错。mapred-site.xml
1
2mv /usr/local/hadoop-2.7.6/etc/hadoop/mapred-site.xml.template /usr/local/hadoop-2.7.6/etc/hadoop/mapred-site.xml
vim /usr/local/hadoop-2.7.6/etc/hadoop/mapred-site.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>yarn-site.xml
1
vim /usr/local/hadoop-2.7.6/etc/hadoop/yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>hadoop-env.sh
1
vim /usr/local/hadoop-2.7.6/etc/hadoop/hadoop-env.sh
1
2
3
4# 将
export JAVA_HOME=${JAVA_HOME}
# 修改为
export JAVA_HOME=/usr/local/jdk1.8.0_181yarn-env.sh
1
vim /usr/local/hadoop-2.7.6/etc/hadoop/yarn-env.sh
1
2
3
4# 将
export JAVA_HOME=/home/y/libexec/jdk1.6.0/
# 修改为
export JAVA_HOME=/usr/local/jdk1.8.0_181mapred-env.sh
1
vim /usr/local/hadoop-2.7.6/etc/hadoop/mapred-env.sh
1
2
3
4# 将
export JAVA_HOME=/home/y/libexec/jdk1.6.0/
# 修改为
export JAVA_HOME=/usr/local/jdk1.8.0_181slaves
1
vim /usr/local/hadoop-2.7.6/etc/hadoop/slaves
1
2# 替换内容为你的所有 slave 节点的域名
slave同步 Hadoop 配置文件至 slave
1
rsync -av /usr/local/hadoop-2.7.6/etc/ slave:/usr/local/hadoop-2.7.6/etc/
Hadoop 环境变量
1
vim /etc/profile.d/hadoop.sh
1
2
3# 添加
export HADOOP_HOME=/usr/local/hadoop-2.7.6
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH1
2# 使之生效
source /etc/profile.d/hadoop.sh1
2
3
4
5
6
7[root@izbp11ddoyj3i3tqpvtim9z local]# hadoop version
Hadoop 2.7.6
Subversion https://shv@git-wip-us.apache.org/repos/asf/hadoop.git -r 085099c66cf28be31604560c376fa282e69282b8
Compiled by kshvachk on 2018-04-18T01:33Z
Compiled with protoc 2.5.0
From source with checksum 71e2695531cb3360ab74598755d036
This command was run using /usr/local/hadoop-2.7.6/share/hadoop/common/hadoop-common-2.7.6.jarscp 到 slave
1
scp /etc/profile.d/hadoop.sh slave:/etc/profile.d/
Slave
Hadoop 环境变量
1
source /etc/profile.d/hadoop.sh
1
2
3
4
5
6
7[root@izbp11ddoyj3i3tqpvtimaz ~]# hadoop version
Hadoop 2.7.6
Subversion https://shv@git-wip-us.apache.org/repos/asf/hadoop.git -r 085099c66cf28be31604560c376fa282e69282b8
Compiled by kshvachk on 2018-04-18T01:33Z
Compiled with protoc 2.5.0
From source with checksum 71e2695531cb3360ab74598755d036
This command was run using /usr/local/hadoop-2.7.6/share/hadoop/common/hadoop-common-2.7.6.jar
Hadoop:运行
Master
1
2/usr/local/hadoop-2.7.6/bin/hdfs namenode -format
/usr/local/hadoop-2.7.6/sbin/start-all.sh在执行格式化
-format命令时,要避免 NameNode 的 namespace ID 和 DataNode 的 namespace ID 不一致。这是因为每格式化一次就会产生不同的 Name,Data,Temp 等文件信息,多次格式化会产生不同的 Name,Data,Temp,容易导致 ID 不同,使 Hadoop 不能正常运行。所以每次执行-format命令时,就需要将 DataNode 和 NameNode 上原来的 Data,Temp 文件删除。建议只执行一次格式化。格式化 NameNode 的命令可以执行多次,但是这样会使所有的现有文件系统数据受损。只有在 Hadoop 集群关闭和你想进行格式化的情况下,才能执行格式化。但是在其他大多数情况下,格式化操作会快速,不可恢复地删除 HDFS 上的所有数据。
1
2
3
4
5[root@izbp11ddoyj3i3tqpvtim9z local]# jps
30884 Jps
9769 SecondaryNameNode
9678 NameNode
10159 ResourceManagerSlave
1
2
3
4[root@izbp11ddoyj3i3tqpvtimaz ~]# jps
3462 Jps
13994 DataNode
14556 NodeManager
Hadoop:检查是否成功运行
Web UI 检查是否正常启动
master:50070NameNode 和 DataNode 节点是否成功master:8088Yarn 服务是否正常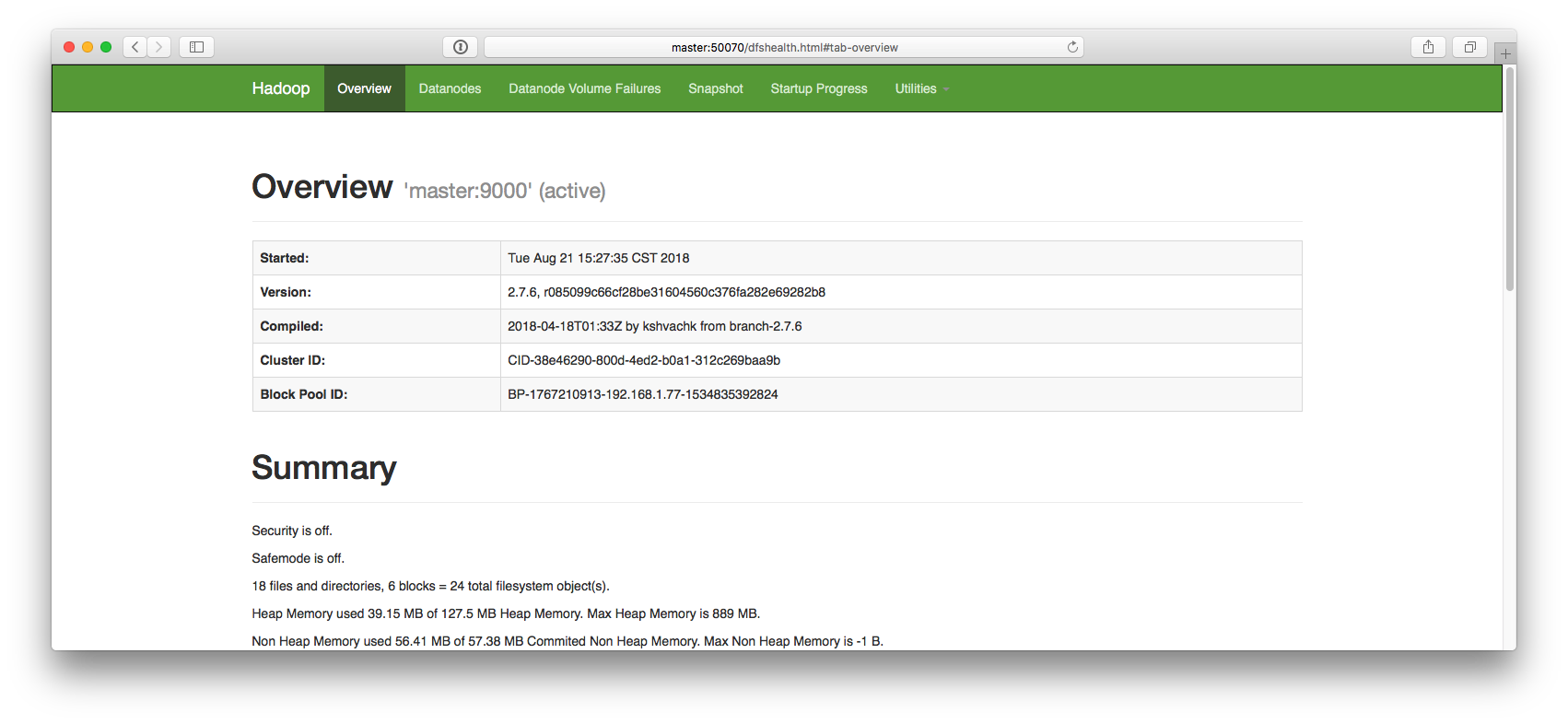
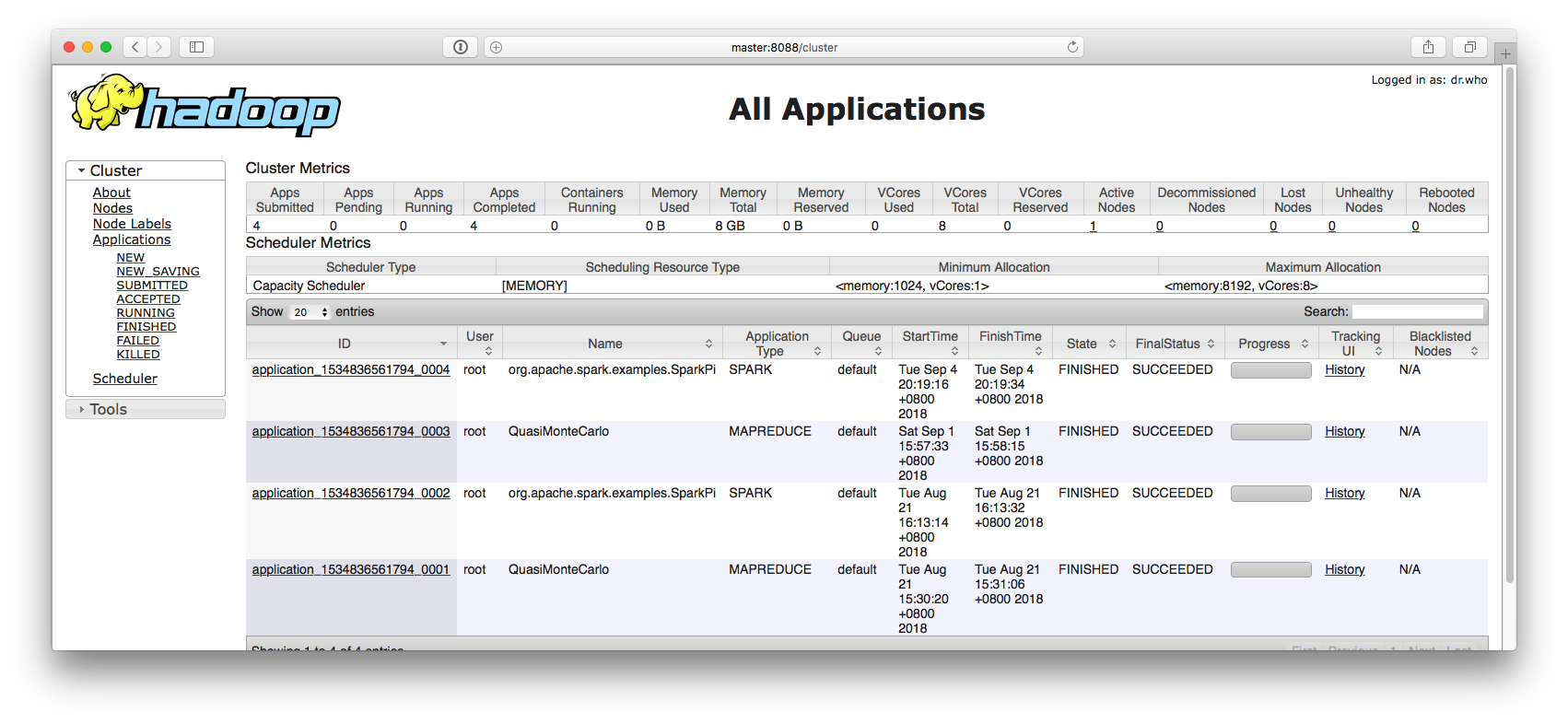
跑 PI 实例检查集群是否成功
1
2cd /usr/local/hadoop-2.7.6/
bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar pi 10 101
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88[root@izbp11ddoyj3i3tqpvtim9z hadoop-2.7.6]# bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar pi 10 10
Number of Maps = 10
Samples per Map = 10
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
18/09/01 15:57:32 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.1.77:8032
18/09/01 15:57:32 INFO input.FileInputFormat: Total input paths to process : 10
18/09/01 15:57:33 INFO mapreduce.JobSubmitter: number of splits:10
18/09/01 15:57:33 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1534836561794_0003
18/09/01 15:57:33 INFO impl.YarnClientImpl: Submitted application application_1534836561794_0003
18/09/01 15:57:33 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1534836561794_0003/
18/09/01 15:57:33 INFO mapreduce.Job: Running job: job_1534836561794_0003
18/09/01 15:57:40 INFO mapreduce.Job: Job job_1534836561794_0003 running in uber mode : false
18/09/01 15:57:40 INFO mapreduce.Job: map 0% reduce 0%
18/09/01 15:58:00 INFO mapreduce.Job: map 40% reduce 0%
18/09/01 15:58:01 INFO mapreduce.Job: map 60% reduce 0%
18/09/01 15:58:13 INFO mapreduce.Job: map 70% reduce 0%
18/09/01 15:58:14 INFO mapreduce.Job: map 90% reduce 0%
18/09/01 15:58:15 INFO mapreduce.Job: map 100% reduce 0%
18/09/01 15:58:16 INFO mapreduce.Job: map 100% reduce 100%
18/09/01 15:58:17 INFO mapreduce.Job: Job job_1534836561794_0003 completed successfully
18/09/01 15:58:17 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=226
FILE: Number of bytes written=1354397
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2610
HDFS: Number of bytes written=215
HDFS: Number of read operations=43
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=10
Launched reduce tasks=1
Data-local map tasks=10
Total time spent by all maps in occupied slots (ms)=158717
Total time spent by all reduces in occupied slots (ms)=13606
Total time spent by all map tasks (ms)=158717
Total time spent by all reduce tasks (ms)=13606
Total vcore-milliseconds taken by all map tasks=158717
Total vcore-milliseconds taken by all reduce tasks=13606
Total megabyte-milliseconds taken by all map tasks=162526208
Total megabyte-milliseconds taken by all reduce tasks=13932544
Map-Reduce Framework
Map input records=10
Map output records=20
Map output bytes=180
Map output materialized bytes=280
Input split bytes=1430
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=280
Reduce input records=20
Reduce output records=0
Spilled Records=40
Shuffled Maps =10
Failed Shuffles=0
Merged Map outputs=10
GC time elapsed (ms)=4039
CPU time spent (ms)=6420
Physical memory (bytes) snapshot=2867822592
Virtual memory (bytes) snapshot=23364702208
Total committed heap usage (bytes)=2161639424
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1180
File Output Format Counters
Bytes Written=97
Job Finished in 45.255 seconds
Estimated value of Pi is 3.20000000000000000000停止 Hadoop 集群
1
/usr/local/hadoop-2.7.6/sbin/stop-all.sh
Spark:安装 Scala
Master
- Scala 2.10.6, 下载地址
下载解压
1
2
3wget http://downloads.lightbend.com/scala/2.10.6/scala-2.10.6.tgz
tar -zxvf scala-2.10.6.tgz
mv scala-2.10.6 /usr/localscala 环境变量
1
vim /etc/profile.d/scala.sh
1
2export SCALA_HOME=/usr/local/scala-2.10.6
export PATH=$PATH:$SCALA_HOME/bin1
source /etc/profile.d/scala.sh
1
2[root@izbp11ddoyj3i3tqpvtim9z ~]# scala -version
Scala code runner version 2.10.6 -- Copyright 2002-2013, LAMP/EPFL同步到 Slave
1
2rsync -av /usr/local/scala-2.10.6/ slave:/usr/local/
scp /etc/profile.d/scala.sh slave:/etc/profile.d/
Slave
1
source /etc/profile.d/scala.sh
1
2[root@izbp11ddoyj3i3tqpvtimaz ~]# scala -version
Scala code runner version 2.10.6 -- Copyright 2002-2013, LAMP/EPFL
Spark:安装
Master
- Spark 1.5.2, 下载地址
下载解压
1
2
3wget http://archive.apache.org/dist/spark/spark-1.5.2/spark-1.5.2-bin-hadoop2.6.tgz
tar -zxvf spark-1.5.2-bin-hadoop2.6.tgz
mv spark-1.5.2-bin-hadoop2.6 /usr/local/Spark 环境变量
1
vim /etc/profile.d/spark.sh
1
2
3
4
5export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR==$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/usr/local/spark-1.5.2-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin1
source /etc/profile.d/spark.sh
同步到 Slave
1
2rsync -av /usr/local/spark-1.5.2-bin-hadoop2.6/ slave:/usr/local/
scp /etc/profile.d/spark.sh slave:/etc/profile.d/
Slave
1
source /etc/profile.d/spark.sh
Spark:配置
Master
conf/slaves
1
2cp /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slaves.template /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slaves
vim /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slaves1
2
3
4# A Spark Worker will be started on each of the machines listed below.
# localhost
master
slaveconf/spark-env.sh
1
vim /usr/local/spark-1.5.2-bin-hadoop2.6/conf/spark-env.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16export JAVA_HOME=/usr/local/jdk1.8.0_181
export SCALA_HOME=/usr/local/scala-2.10.6
export HADOOP_HOME=/usr/local/hadoop-2.7.6
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# If not SPARK_PID_DIR, YARN_PID_DIR, HADOOP_PID_DIR , It will cause exception about "no org.apache.spark.deploy.master.Master to stop"
export SPARK_PID_DIR=/usr/local/spark-1.5.2-bin-hadoop2.6/app/pids
export YARN_PID_DIR=/usr/local/spark-1.5.2-bin-hadoop2.6/app/pids
export HADOOP_PID_DIR==/usr/local/spark-1.5.2-bin-hadoop2.6/app/pids
export SPARK_MASTER_IP=192.168.1.77
export SPARK_MASTER_HOST=192.168.1.77
export SPARK_MASTER_PORT=7077
export SPARK_LOCAL_IP=192.168.1.77
export SPARK_WORKER_CORE=2
export SPARK_WORKER_MEMORY=6g
export PYSPARK_PYTHON=/usr/bin/python
Spark:运行
Master
启动集群
1
cd /usr/local/spark-1.5.2-bin-hadoop2.6/sbin
1
./start-all.sh
1
2
3
4[root@izbp11ddoyj3i3tqpvtim9z sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark-1.5.2-bin-hadoop2.6/sbin/../logs/spark-root-org.apache.spark.deploy.master.Master-1-izbp11ddoyj3i3tqpvtim9z.out
slave: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.5.2-bin-hadoop2.6/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-izbp11ddoyj3i3tqpvtimaz.out
master: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.5.2-bin-hadoop2.6/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-izbp11ddoyj3i3tqpvtim9z.out停止集群
1
2
3
4[root@izbp11ddoyj3i3tqpvtim9z sbin]# ./stop-all.sh
slave: stopping org.apache.spark.deploy.worker.Worker
master: stopping org.apache.spark.deploy.worker.Worker
stopping org.apache.spark.deploy.master.Master
Spark:检查是否成功运行
- Spark Console 界面
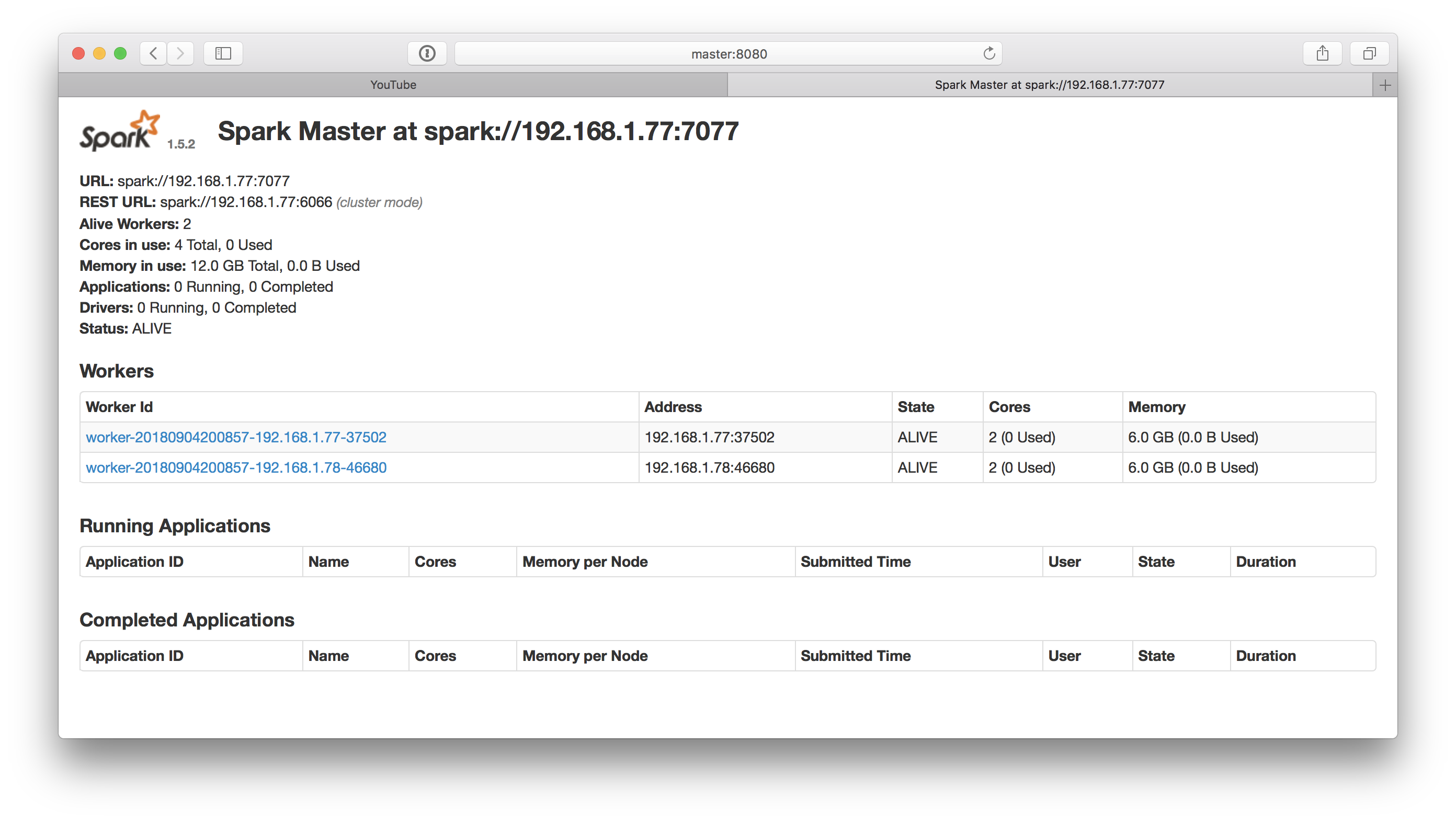
能看到两个 Worker State 为 ALIVE 时,说明你的分布式集群已经搭建成功了,接下来 submit demo 来测试一下。
Submit examples
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67[root@izbp11ddoyj3i3tqpvtim9z spark-1.5.2-bin-hadoop2.6]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster lib/spark-examples*.jar 10
18/09/04 20:19:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/09/04 20:19:13 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.1.77:8032
18/09/04 20:19:13 INFO yarn.Client: Requesting a new application from cluster with 1 NodeManagers
18/09/04 20:19:13 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
18/09/04 20:19:13 INFO yarn.Client: Will allocate AM container, with 1408 MB memory including 384 MB overhead
18/09/04 20:19:13 INFO yarn.Client: Setting up container launch context for our AM
18/09/04 20:19:13 INFO yarn.Client: Setting up the launch environment for our AM container
18/09/04 20:19:13 INFO yarn.Client: Preparing resources for our AM container
18/09/04 20:19:14 INFO yarn.Client: Uploading resource file:/usr/local/spark-1.5.2-bin-hadoop2.6/lib/spark-assembly-1.5.2-hadoop2.6.0.jar -> hdfs://master:9000/user/root/.sparkStaging/application_1534836561794_0004/spark-assembly-1.5.2-hadoop2.6.0.jar
18/09/04 20:19:15 INFO yarn.Client: Uploading resource file:/usr/local/spark-1.5.2-bin-hadoop2.6/lib/spark-examples-1.5.2-hadoop2.6.0.jar -> hdfs://master:9000/user/root/.sparkStaging/application_1534836561794_0004/spark-examples-1.5.2-hadoop2.6.0.jar
18/09/04 20:19:15 INFO yarn.Client: Uploading resource file:/tmp/spark-368edc00-f27b-42b0-87fa-0fba1b79f8b1/__spark_conf__2041701267374277539.zip -> hdfs://master:9000/user/root/.sparkStaging/application_1534836561794_0004/__spark_conf__2041701267374277539.zip
18/09/04 20:19:16 INFO spark.SecurityManager: Changing view acls to: root
18/09/04 20:19:16 INFO spark.SecurityManager: Changing modify acls to: root
18/09/04 20:19:16 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
18/09/04 20:19:16 INFO yarn.Client: Submitting application 4 to ResourceManager
18/09/04 20:19:16 INFO impl.YarnClientImpl: Submitted application application_1534836561794_0004
18/09/04 20:19:17 INFO yarn.Client: Application report for application_1534836561794_0004 (state: ACCEPTED)
18/09/04 20:19:17 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1536063556641
final status: UNDEFINED
tracking URL: http://master:8088/proxy/application_1534836561794_0004/
user: root
18/09/04 20:19:18 INFO yarn.Client: Application report for application_1534836561794_0004 (state: ACCEPTED)
18/09/04 20:19:19 INFO yarn.Client: Application report for application_1534836561794_0004 (state: ACCEPTED)
18/09/04 20:19:20 INFO yarn.Client: Application report for application_1534836561794_0004 (state: ACCEPTED)
18/09/04 20:19:21 INFO yarn.Client: Application report for application_1534836561794_0004 (state: ACCEPTED)
18/09/04 20:19:22 INFO yarn.Client: Application report for application_1534836561794_0004 (state: RUNNING)
18/09/04 20:19:22 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.1.78
ApplicationMaster RPC port: 0
queue: default
start time: 1536063556641
final status: UNDEFINED
tracking URL: http://master:8088/proxy/application_1534836561794_0004/
user: root
18/09/04 20:19:23 INFO yarn.Client: Application report for application_1534836561794_0004 (state: RUNNING)
18/09/04 20:19:24 INFO yarn.Client: Application report for application_1534836561794_0004 (state: RUNNING)
18/09/04 20:19:25 INFO yarn.Client: Application report for application_1534836561794_0004 (state: RUNNING)
18/09/04 20:19:26 INFO yarn.Client: Application report for application_1534836561794_0004 (state: RUNNING)
18/09/04 20:19:27 INFO yarn.Client: Application report for application_1534836561794_0004 (state: RUNNING)
18/09/04 20:19:28 INFO yarn.Client: Application report for application_1534836561794_0004 (state: RUNNING)
18/09/04 20:19:29 INFO yarn.Client: Application report for application_1534836561794_0004 (state: RUNNING)
18/09/04 20:19:30 INFO yarn.Client: Application report for application_1534836561794_0004 (state: RUNNING)
18/09/04 20:19:31 INFO yarn.Client: Application report for application_1534836561794_0004 (state: RUNNING)
18/09/04 20:19:32 INFO yarn.Client: Application report for application_1534836561794_0004 (state: RUNNING)
18/09/04 20:19:33 INFO yarn.Client: Application report for application_1534836561794_0004 (state: RUNNING)
18/09/04 20:19:34 INFO yarn.Client: Application report for application_1534836561794_0004 (state: FINISHED)
18/09/04 20:19:34 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.1.78
ApplicationMaster RPC port: 0
queue: default
start time: 1536063556641
final status: SUCCEEDED
tracking URL: http://master:8088/proxy/application_1534836561794_0004/
user: root
18/09/04 20:19:34 INFO util.ShutdownHookManager: Shutdown hook called
18/09/04 20:19:34 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-368edc00-f27b-42b0-87fa-0fba1b79f8b1
Spark:安装问题汇总
pyspark 配置问题
Spark PYSPARK_PYTHON=/path/to/python2.7 (可在环境变量中设置,也可在spark-env.sh中设置)
Exception: Randomness of hash of string should be disabled via PYTHONHASHSEED
需要配置 SPARKHOME ./conf文件夹下的 spark-defaults.conf,将spark.executorEnv.PYTHONHASHSEED 0 #具体值可以自己设置加入到上面的配置文件中
java.lang.NoClassDefFoundError: org/apache/spark/Logging
Spark 版本过高 2.5 降到 1.5 ,从 Spark 1.5 版本之后都会出现此错误
org.apache.spark.Logging is available in Spark version 1.5.2 or lower version.spark1.5 root@localhost’s password:localhost:permission denied,please try again
编辑配置文件,允许以 root 用户通过 ssh 登录:sudo vi /etc/ssh/sshd_config
找到:PermitRootLogin prohibit-password禁用
添加:PermitRootLogin yesError: Cannot find configuration directory: /etc/hadoop
引用:https://blog.csdn.net/haozhao_blog/article/details/50767009
Spark 无法获得 Slave 节点的 Worker 信息
spark-env.sh 中关于 Master Worker 的值一律写 IP 地址,而不是域名
比如 SPARK_MASTER_IP 和 SPARK_MASTER_HOST 都要写成 IP 地址集群启动一段时间后,无法停止
原因参见 Spark集群无法停止的原因分析和解决如果已发生:每个节点
ps -aux | grep spark之后,手动 kill 进程在 spark-env.sh 中,添加如下配置:
1
2
3export SPARK_PID_DIR=/usr/local/spark-1.5.2-bin-hadoop2.6/app/pids
export YARN_PID_DIR=/usr/local/spark-1.5.2-bin-hadoop2.6/app/pids
export HADOOP_PID_DIR==/usr/local/spark-1.5.2-bin-hadoop2.6/app/pids