
省下 700 万的数据治理方案总结
在大经济环境整体下行的今天,互联网行业引来了寒冬,「今年是很艰难的一年,但也是未来十年最好的一年」之类的声音也越来越多。连背靠大山的华为,也把「活下来」作为了未来主要的纲领。
所以集团内部从去年开始,也分分打破大锅饭模式,各个业务线开始实行经营责任制,自负盈亏。
而当业务增长跟不上数据增长,就会导致数据生产带来的技术成本比不上数据给业务带来的价值,造成妥妥的技术资源的浪费。基于此,我们团队内部开始了为期半年的数据成本治理专项,最终使数据成本在半年内降低了 700 万。
这里总结一下大致的思路,也算给自己转岗前的一次复盘。
第一阶段:头部大任务 & 尾部无效任务治理
1.1 大任务优化
通过元数据分析头部任务属于哪些类型,针对性的优化大任务,我们刚开始的大任务主要是一些业务同学跑数SQL的任务(技术跑数一般比较遵守规范,业务同学经常有以为自己会两句SQL就瞎写代码的情况)
这些不合理的SQL任务,80%可以归因到「暴力扫描」,即业务取数过程中,没有指定合理的取数范围,导致经常取到几年前的数据,而业务本身却并不需要,造成了很大的浪费。
另外一种情况则是「不合理访问全量表」,明明只访问几天的数据,而且有增量表可以访问,却去访问了全量表,全量表一天的分区就是PB级别,光是SELECT一次就要耗费巨大的机器资源,这类SQL也是要被干掉的。
针对这些情况,目前我们分三个阶段优化:
1)事前对业务同学做好培训,在给他们权限之前,必须经过SQL用数规范考核。并且在业务提交代码时,引入检查器机制,判断分区数是否合理,并根据关键字预估费用。
2)事中监控不合理跑数任务,针对跑数时间过长,跑数消耗CU过多的任务,配置自动查杀,避免超长超大任务产出。
3)事后监控任务 or SQL 粒度的跑数情况,针对一些写数不规范的用户,通知整改,整改过程中,暂时回收权限。
1.2 历史任务下线
针对离线表,一些长期在线上的没人管也没有迭代的任务,我们也进行一波下线,具体规则如下:
- 代码两年未更新
- (且)下游无真实消费场景
- (或)产出的表超过一个月无人访问
针对 OLAP 库,我们也针对性的做了分区和索引的治理
分区:由于 OLAP 库底层存储是 SSD,所以他的存储费用是传统离线表的 20 倍,所以 OLAP 库不应保存太长的数据,我们根据历史访问分区情况,缩减分区。
索引:只保持 *_code 列作为索引,所有 *_name 列且 STRING 类型的列,全部剔除。
第二阶段:腰部任务治理,控制整体费用往下压
2.1 错峰调度
- 为什么要错峰调度
- 任务都挤在凌晨阶段跑,导致凌晨资源超卖高,白天资源空闲,导致 quota 整体闲置率比较高,影响 quota 整体稳定性
- 顺应今年集团收费模式,工作日 12:00-14:00,19:00-24:00 为闲时收费时段,费用打 9 折
什么样的任务会被错峰
1)1、3级基线任务
2)(且)发布时间大于 1个月的任务
3)(且)日均消耗 CU > 5
4)(且)日均任务耗时 > 100 分钟
5)(或)日常巡检发现的不合理任务错峰调度的策略
命中上述条件的任务,首先会被统一安排在每天 12:00 起调(集群白天闲时),之后如果没有反馈,会不定期的延后到 13:00,14:00… 19:00,直到被暂停错峰效果
错峰前:资源从凌晨开始排队,集群使用率一直处于比较高的水位,而下午之后,集群水位又迅速降低到了保障线以下,潮汐效应严重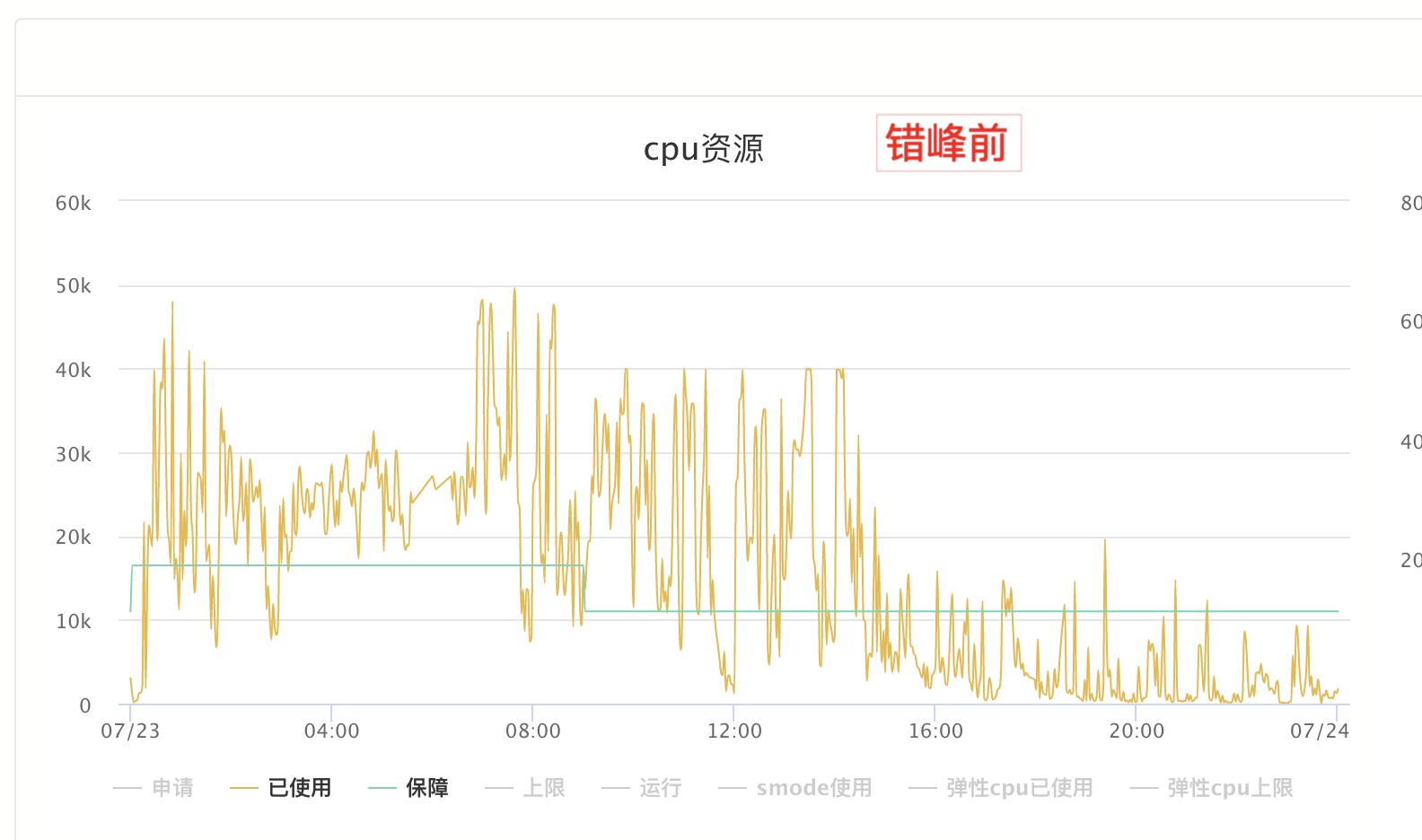
错峰后:原本凌晨阶段调度的非重要任务,挪到12点/19点以后起调,使得凌晨集群资源能保障分配到重要任务上,而且也把白天时段空闲的资源利用了起来,提高了集群整体的利用率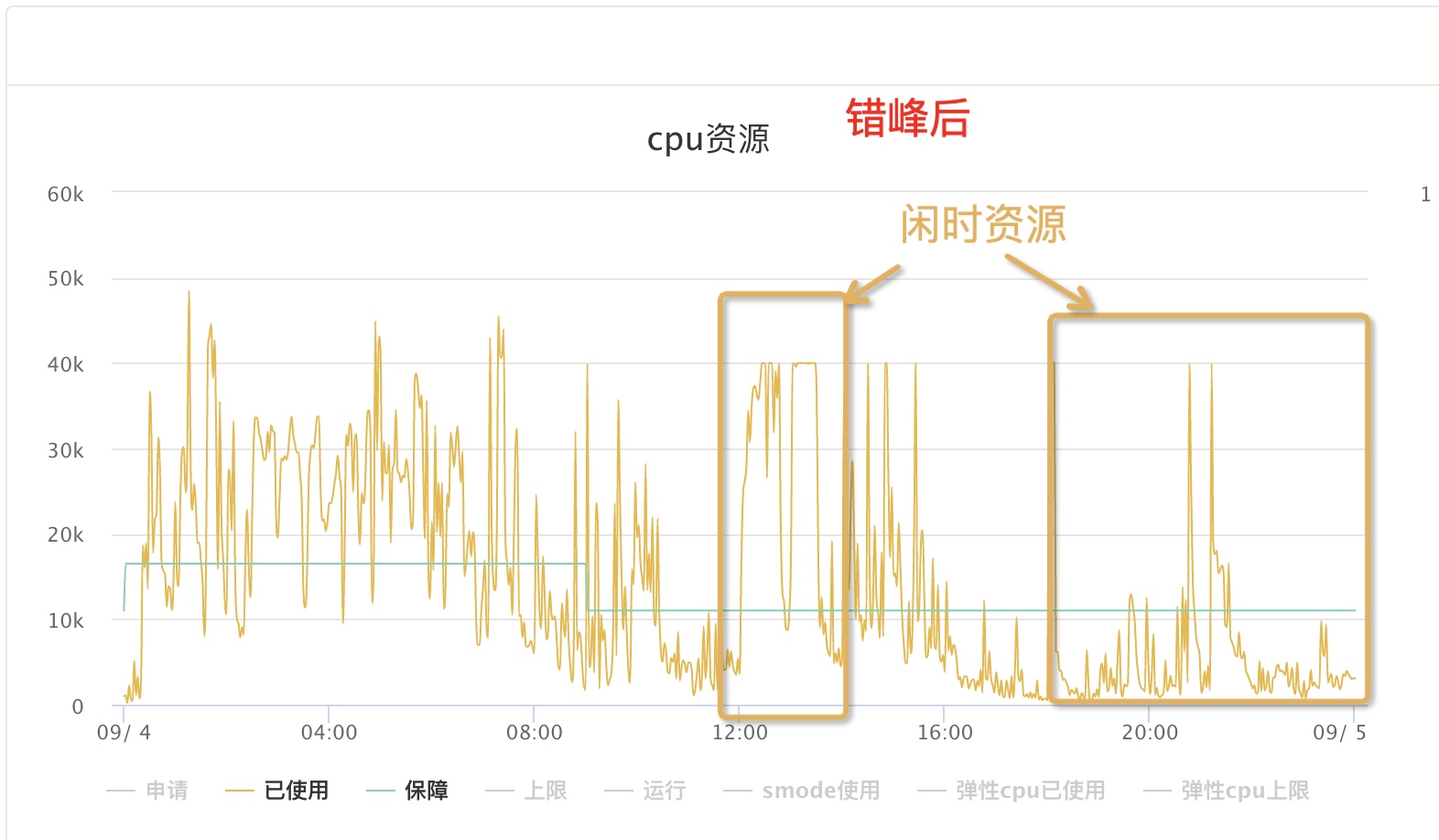
第三阶段:从业务视角出发,通过业务价值优化跑数行为
3.1 基于业务视角的数据治理
上面两步算是比较传统和通用的数据治理方案,而第三阶段我认为这是一个全新的尝试,结合数据产品自身的价值与技术成本之间的关系,以低业务价值驱动上游数据节点资产的治理。
基于该思路,我们探索出四步来实现这一目标:

- 实现从产品侧到技术侧的全链路血缘
- 基于全链路血缘的成本费用刻画
- 结合量化后的业务变量,产出数据产品 ROI
- 低 ROI 数据全链路节点成本治理
- 3.1.1 全链路血缘
该步骤见我上一篇文章:全链路数据血缘构建及方案
- 3.1.2 节点成本费用分摊
量化每个数据产品(包含报表、接口、计算节点)的技术成本,是该阶段的核心能力,比如某张报表,上游由 OLAP 数据库提供加速能力,再上游是成百上千个离线计算节点通过复杂计算后得到的一系列指标,如何把 OLAP 和离线计算引擎所产生的成本分摊到这张报表上?
基于上面的全链路血缘,我们设计了成本计算算法模型,从最上层父节点产生的存储/计算成本,通过分摊系数承载,由子节点加上父节点分摊后的成本,层层向下,最终体现在末节点,该节点就包含了上游所有依赖节点分摊后的费用。
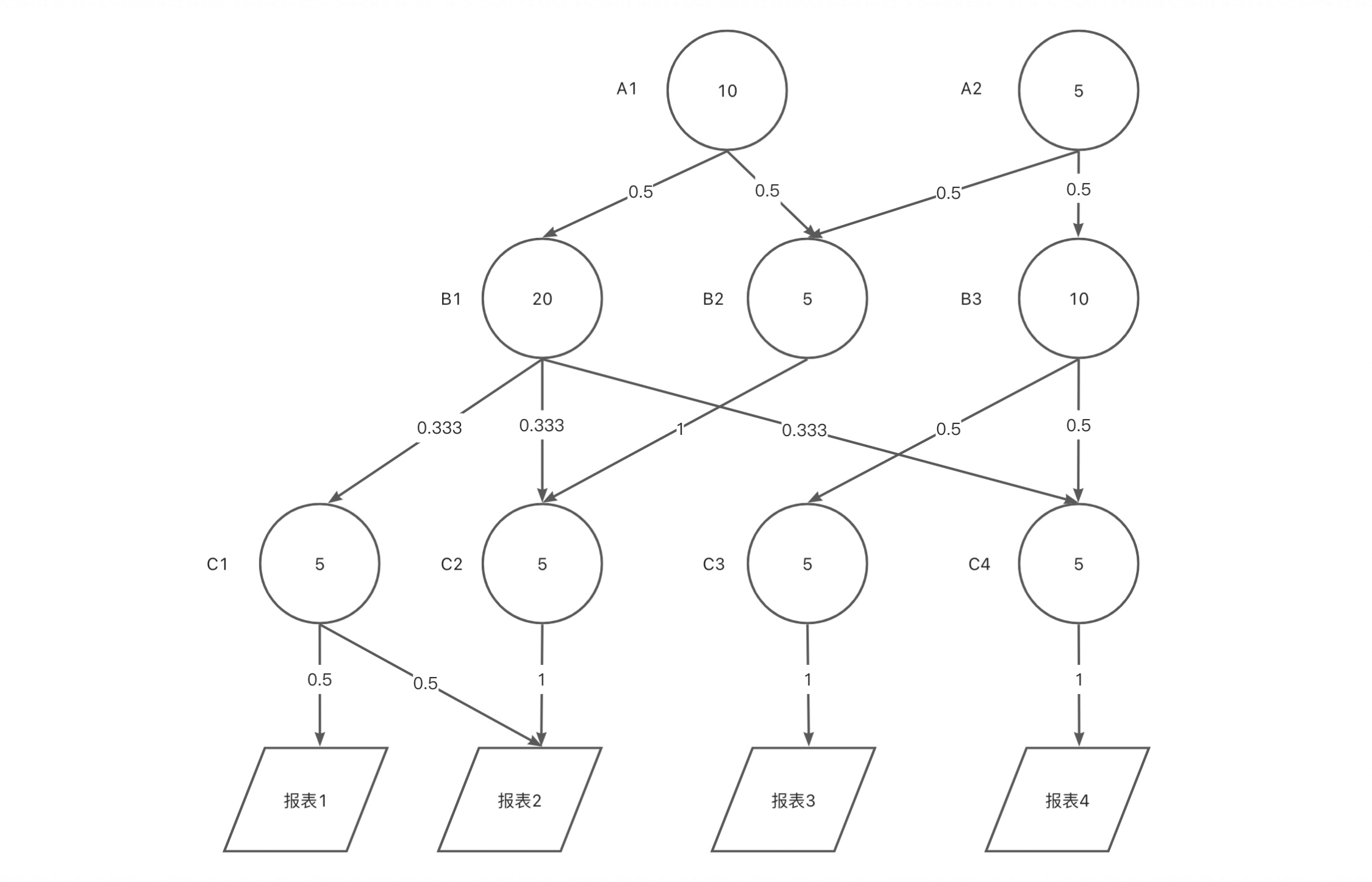
举个例子,结合上图,我们可以算出各个节点分摊后的成本(Axr):
A1r=A1
A2r=A2
B1r=0.5✖️A1r+B1
B2r=0.5✖️A1+0.5✖️A2+B2
B3r=0.5✖️A2
…
报表1=0.5✖️C1r
报表2=0.5✖️C1r + 1✖️C2r
报表3=1✖️C3r
报表4=1✖️C4r
- 3.1.3 数据产品 ROI 衡量
上一部分我们刻画了数据产品的技术成本部分,把上游 离线节点 / OLAP 等成本分摊到了数据产品层面;接下来我们要通过对数据产品本身能量化的业务价值变量,结合技术成本,计算出数据产品价值 ROI。
我们通过选择正负大类变量共同决定数据产品的 ROI
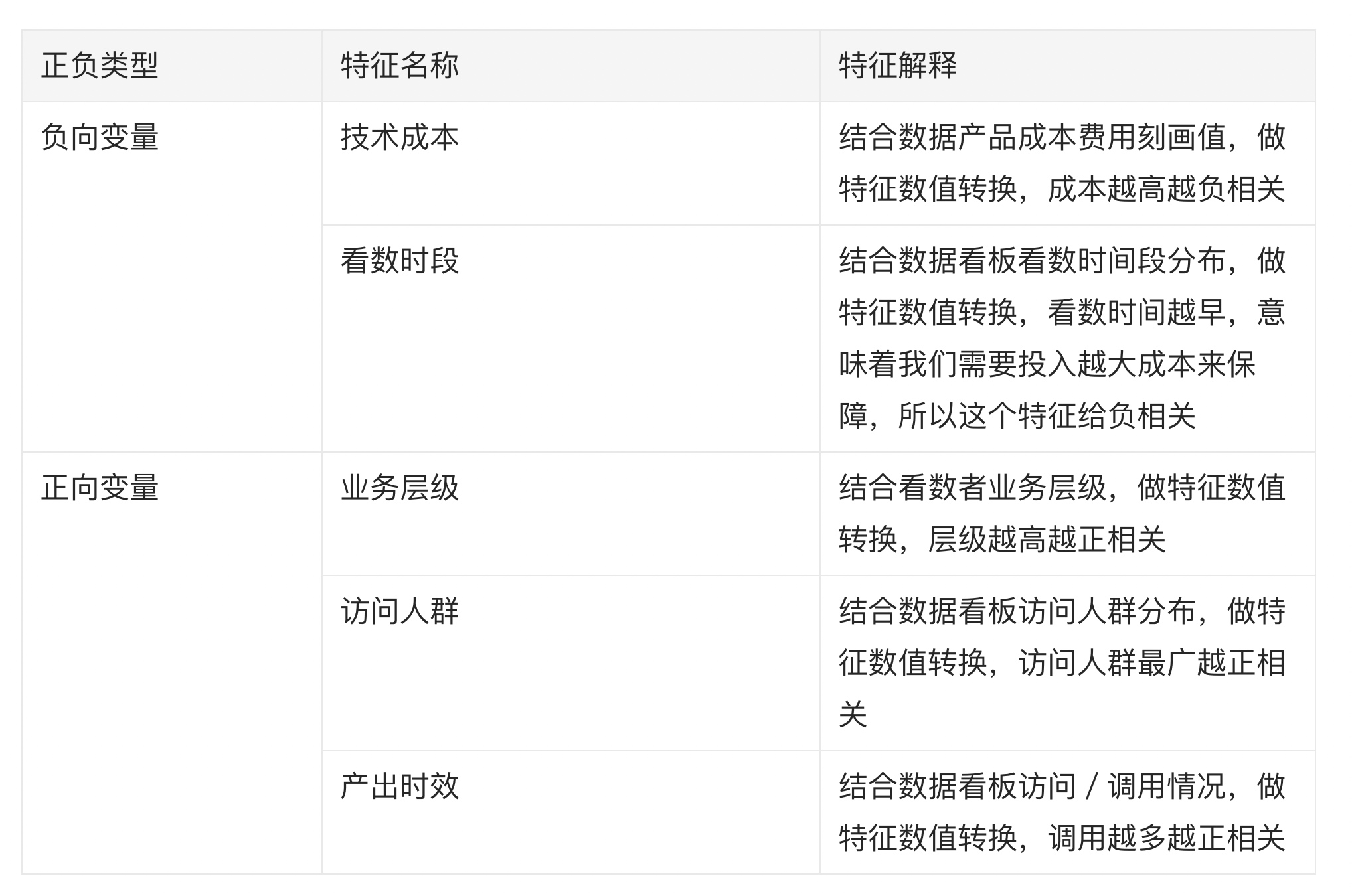
最终我们可以定义 ROI = w1 * 业务层级 + w2 * 访问人群 + w3 * 调用情况 + w4 * 产出时效 + w5 * 技术成本
- 3.1.4 低 ROI 数据全链路节点成本治理
有了基于技术成本和业务视角的 ROI 量化能力,我们就可以基于不同的治理场景,对应有不同的解决方案,从而提供更精细化的治理方案,比如:
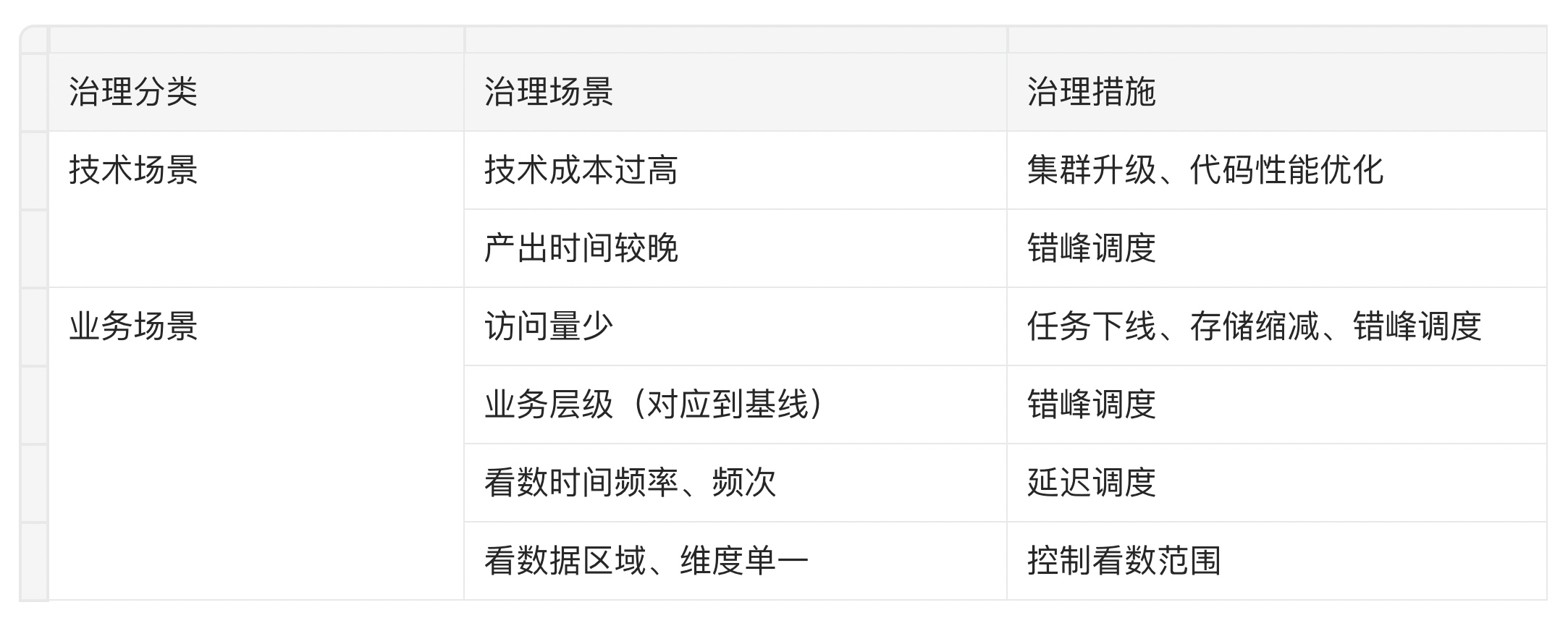
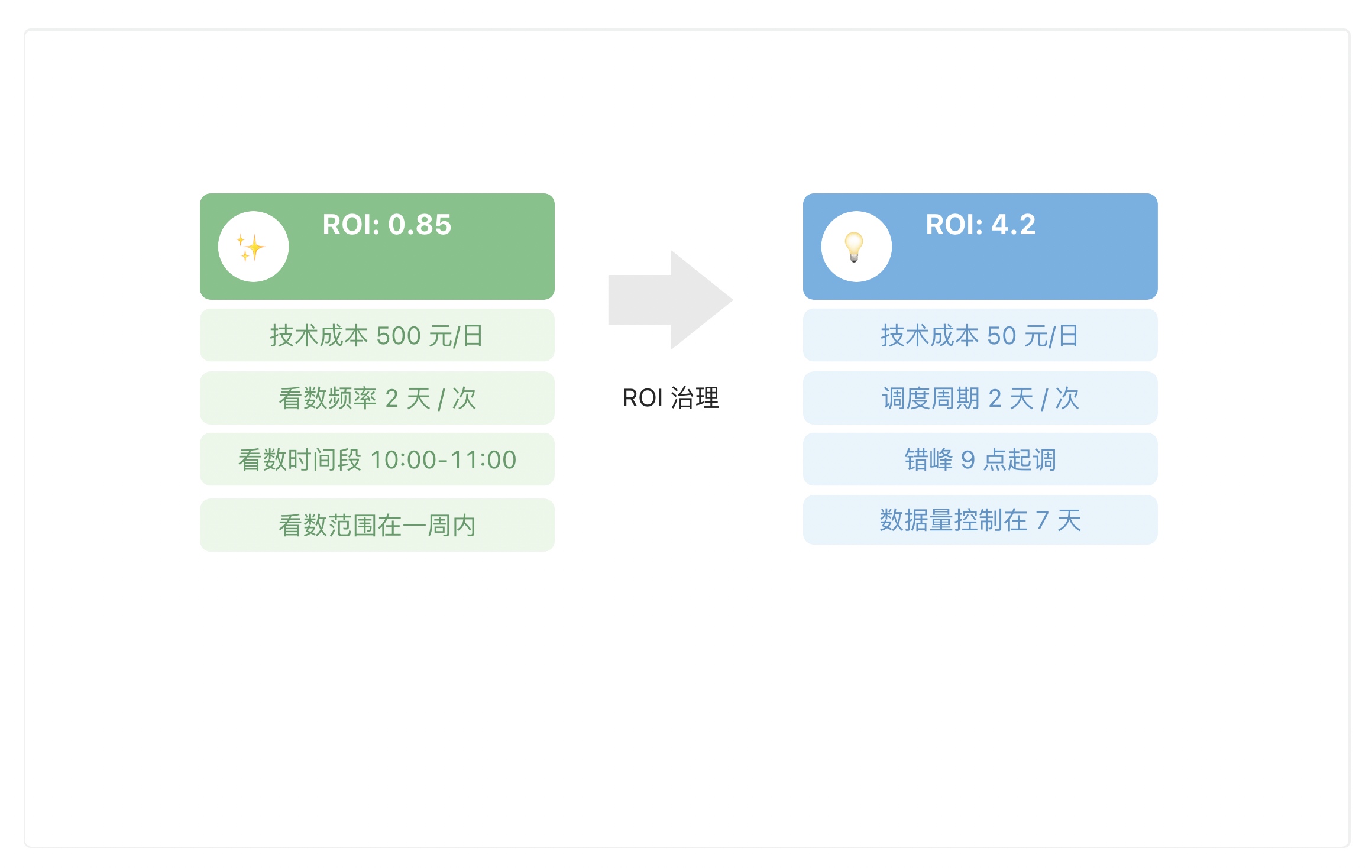
举个例子,针对某个一线小二的数据看板,得到了 ROI 为 0.85,在整体排名中靠后。分析得出上游的离线表每天计算了近一年的数据,同步到了 OLAP ,分摊后看板每天将近花费 500 元的技术成本。但通过业务特征看到该看板平均 2 天才访问 1 次,看数时间段在上午 11 点以后,且每次只取了近一周的数据;我们就可以对上游任务进行优化,通过将任务调度周期设为 2 天,错峰调度至 9 点起调,控制计算数据量在 7 天内等措施,综合性的治理该看板,在不影响业务看数的同时,大幅把计算成本降低到了 50元/日,ROI 也提升至 4.2。
前两阶段已经在我们团队实行并落地了,也取得了比较好的效果。第三阶段目前进行了一半,还没有进行大规模的推广。这个阶段综合性比较强,从对元数据的采集、分摊算法的设计、业务变量对最终结果的影响,再到最后能实现自动化的优化思路,涉及从工程、算法、数据三端的技术。如果做成了至少在数据治理领域一定是个很牛逼的事情。
思路跟领导对过,也得到了认可,而且现在业内做的人也不多,也算是有一定的创新性,可惜我马上要转岗了,也借此记录下来,看新团队后续有没有机会实现第三阶段的治理。
最后想说带来了有什么结果?标题也说了,目前为止已经为团队节省了 700 万,在整个技术降本组内(还包括技术那边的服务器和数据库等)算是贡献度最大的一项了。