数据长尾在分布式数据计算中属于很常见的问题,之前一直没有系统性的做过总结,最近在消化双十一的需求过程中,发现了不少长尾问题,所以也有机会来总结一下常见的长尾问题。
本文主要会记录在 ODPS 计算引擎侧常见的长尾现象以及优化方法。
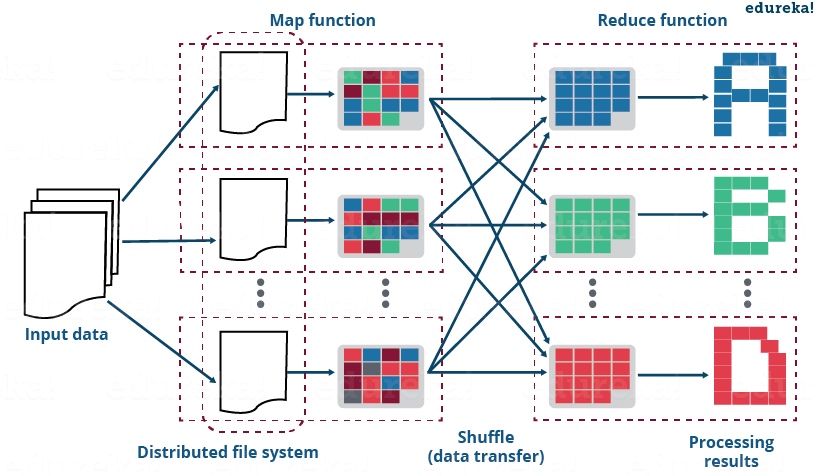
MaxCompute(ODPS)计算本质是 MapReduce 的计算,MapReduce 通常分为三个阶段:Map 阶段、Join 阶段以及 Reduce 阶段,接下来分别针对这三个阶段,来讲讲会出现的长尾现象以及优化思路。

数据长尾在分布式数据计算中属于很常见的问题,之前一直没有系统性的做过总结,最近在消化双十一的需求过程中,发现了不少长尾问题,所以也有机会来总结一下常见的长尾问题。
本文主要会记录在 ODPS 计算引擎侧常见的长尾现象以及优化方法。
MaxCompute(ODPS)计算本质是 MapReduce 的计算,MapReduce 通常分为三个阶段:Map 阶段、Join 阶段以及 Reduce 阶段,接下来分别针对这三个阶段,来讲讲会出现的长尾现象以及优化思路。
在大经济环境整体下行的今天,互联网行业引来了寒冬,「今年是很艰难的一年,但也是未来十年最好的一年」之类的声音也越来越多。连背靠大山的华为,也把「活下来」作为了未来主要的纲领。
所以集团内部从去年开始,也分分打破大锅饭模式,各个业务线开始实行经营责任制,自负盈亏。
而当业务增长跟不上数据增长,就会导致数据生产带来的技术成本比不上数据给业务带来的价值,造成妥妥的技术资源的浪费。基于此,我们团队内部开始了为期半年的数据成本治理专项,最终使数据成本在半年内降低了 700 万。
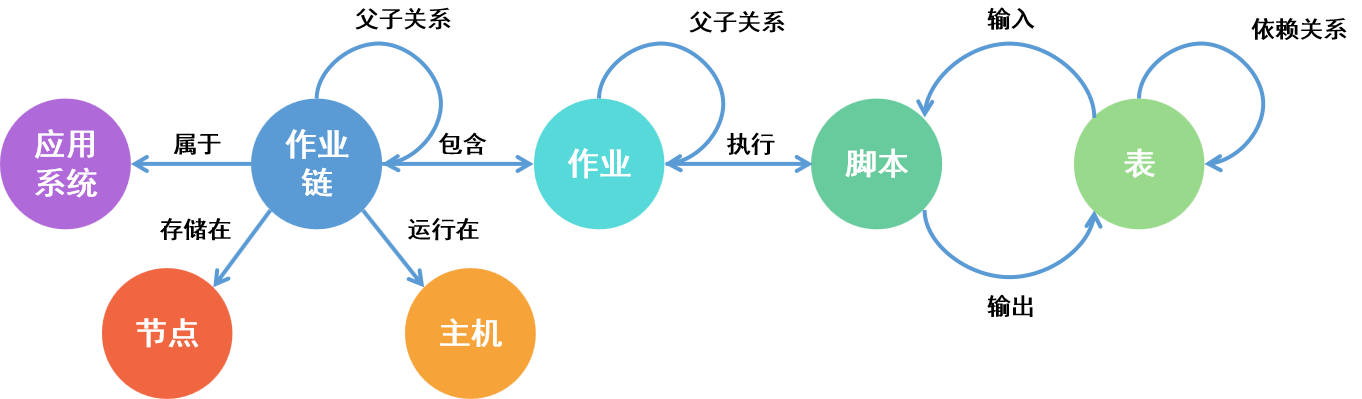
在数据治理,模型升级改造等场景中,我们常常需要通过查找上下游的血缘关系为下线、升级做参考,以往我们只能依托计算平台自身的血缘能力,看到计算节点和数据表之间的血缘关系。但只有这些血缘来分析是不够的,基于数据生产链路,需要清楚的知道数据全链路的流转情况。
条件筛选这一个 Part,主要介绍三种情况:
干巴巴的理论就不说了,我们直接通过例子来开始 SQL 入门之旅吧,这篇讲三个部分:
首先我们需要创建样本数据,假设我们有一张表,这是一张用户信息表,这张表的表名为 s_user_info,具体的表头字段如下:
| 字段 | 字段中文 | 字段示例 |
|---|---|---|
| user_id | 用户编码 | 8374563123 |
| gender | 用户性别 | 男,女 |
| school | 学校名称 | 北京大学 |
| birthday | 用户生日 | 1994-12-10 |
| pay_amt | 支付金额 | 92.45 |
| last_login_time | 上一次登录时间 | 2021-09-30 18:23:48 |
我们就可以创建下面的一个数据集,该数据集一共有 5 列字段, 10 行数据
写博客的目的为了找工作显得很「专业」?还是为了真的能总结些东西…
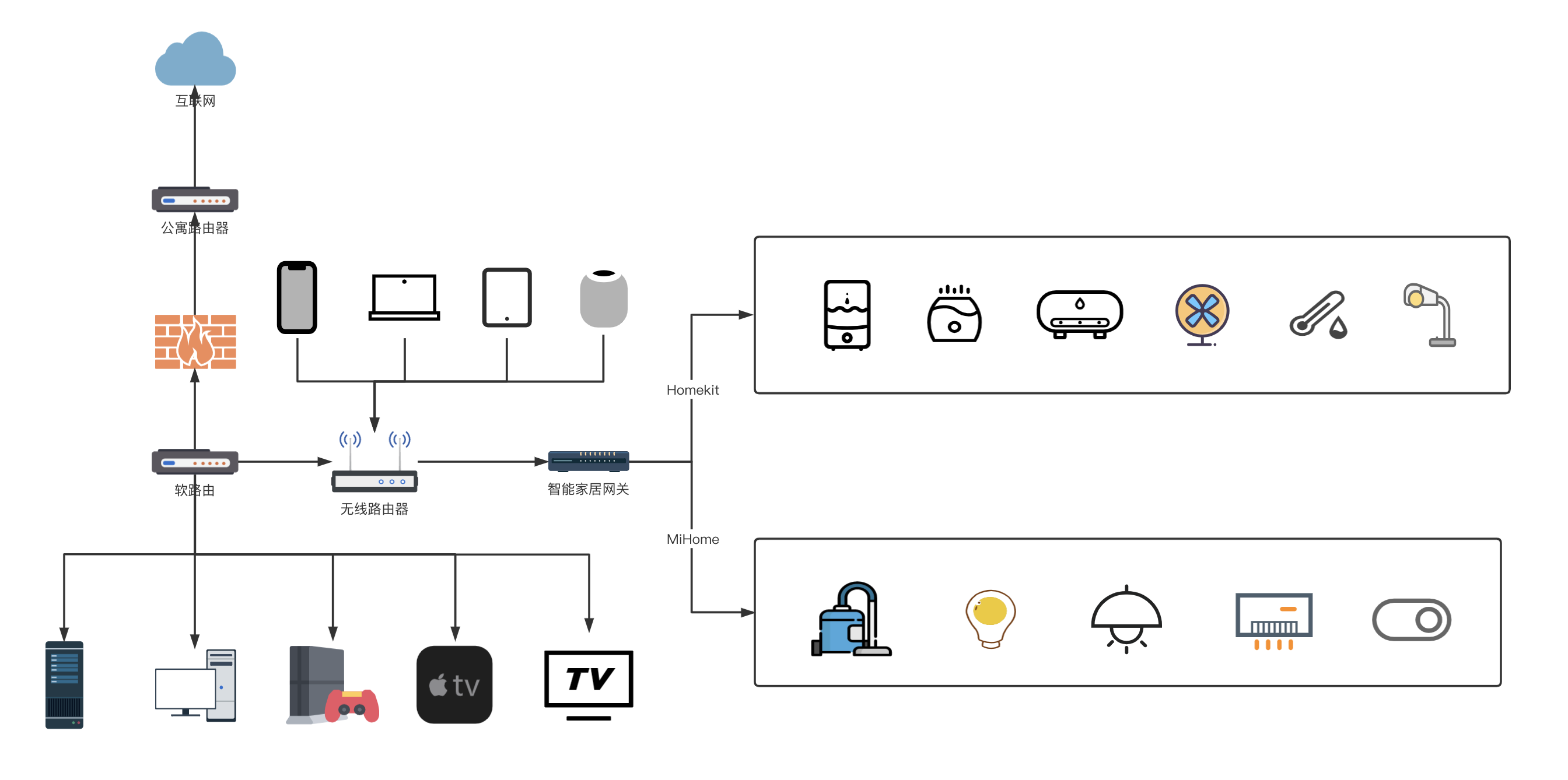
年初的时候升级了家里的网络,捣鼓了软路由 + 硬路由的各种组合方式,又在全屋范围内升级了一系列的智能家居,故来记录一下
由于目前还是租房狗,所以活动范围也只有一个主卧的大小,单路由已经可以完全覆盖,所以目前没有设计无线 AP 或 Mesh 网络。
目前房间内的整体网络拓扑图如下图:
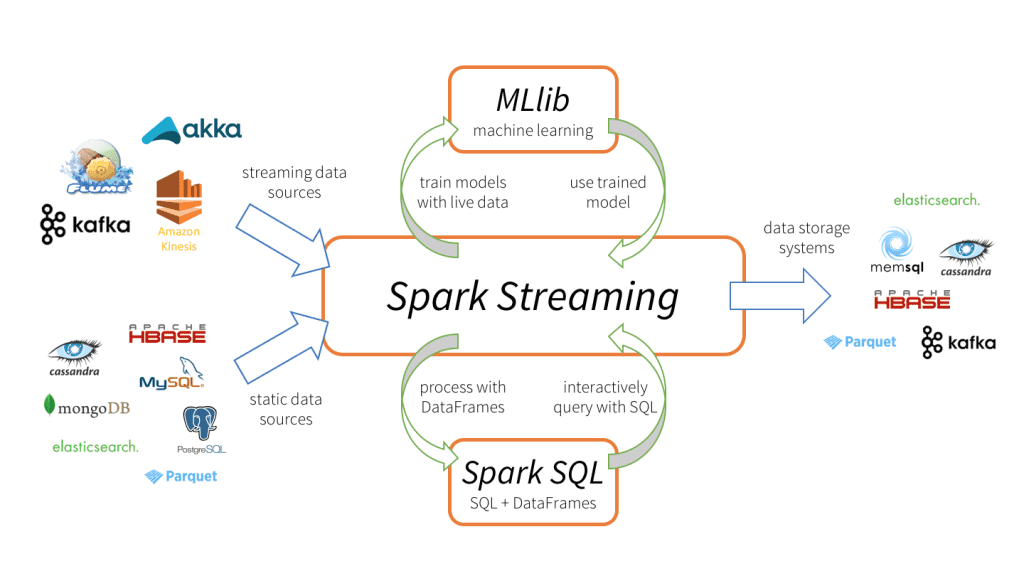
由于数据时效性的原因,实时预测在生产上越来越重要,Spark ML 模型中,常见的实时预测方案有两种:
本文介绍第二种方法,通过 spark streaming 订阅 kakfa 消息,加载 spark ml 模型,实时进行特征转换及预测。
Spark Streaming 作为 Spark 组建之一,可以无缝集成 Spark ML 和 Spark SQL。
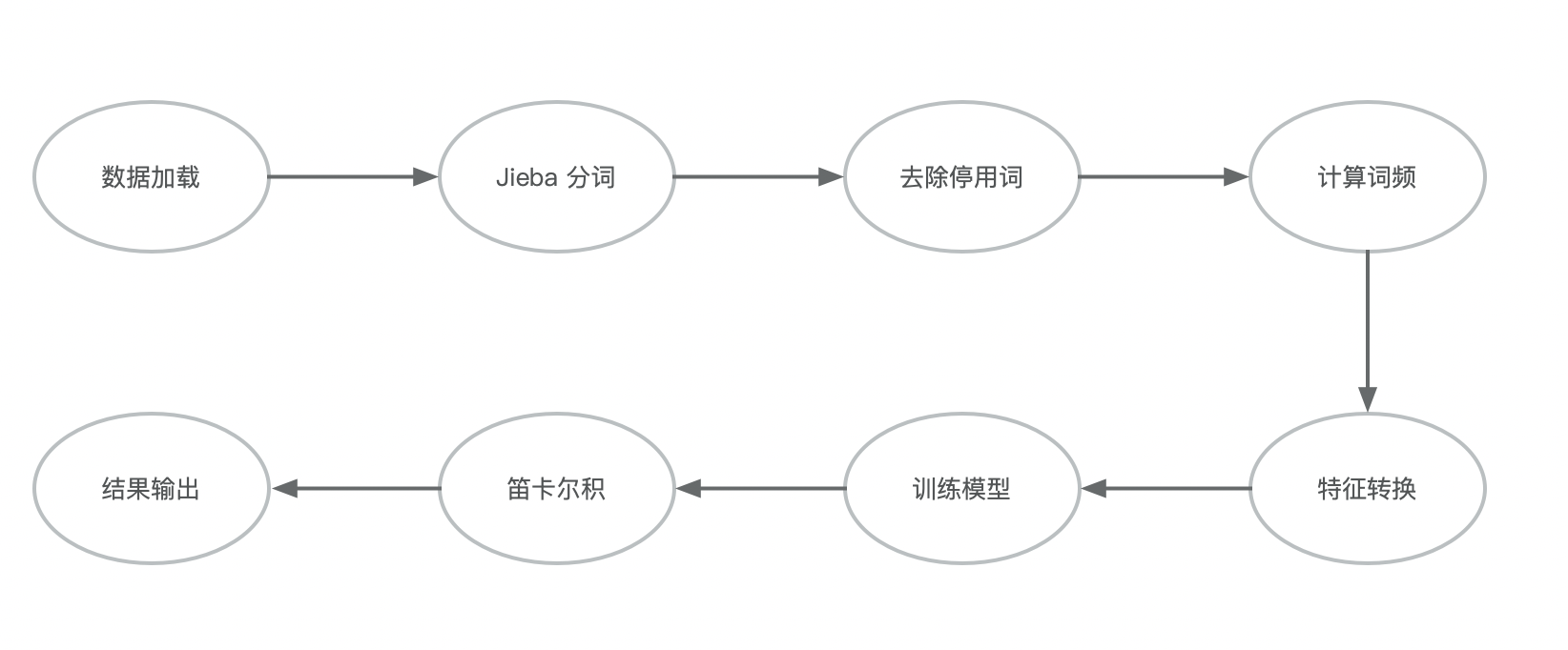
最近在做短视频的相似视频推荐,初期不涉及语义分析及图像检测,所有单纯使用视频标题作为文本,来度量视频库中的相似视频,baseline 选择了使用 Jarccard 相似系数,简单而且效果明显。
整体步骤可以参考下图:
用 Spark 做特征工程时,推荐可以先看下下面的文档
Extracting, transforming and selecting features - Spark 2.3.1 Documentation
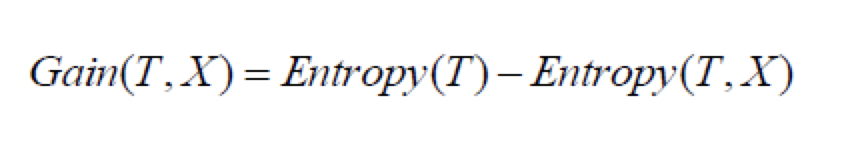
特征工程是整个推荐算法开发过程中比较重要的环节,如何在海量特征中找到有效的特征,可以利用决策树的细想,决策树本身就是通过信息增益(ID3),信息增益比(C4.5),基尼系数(CART)来选择最优特征来作为叶子结点,本文主要介绍如何通过计算 信息增益 来进行特征选择。